
안녕하세요 늑대양입니다 :)
이번 주는 지난 주에 이어서 SQL 학습을 진행합니다!
오늘은 [AI 데이터 사이언티스트 취업 완성 과정]의 19일차 일과를 정리하여 안내해드리도록 하겠습니다.

Day 19 시간표:
- 오프라인 강의: 빅데이터 추출/가공을 위한 SQL 기초
- 오프라인 강의: 빅데이터 추출/가공을 위한 SQL 기초
- 선택학습
Day 19. SQL 기초
빅데이터 추출/가공을 위한 SQL 기초:
지난 시간 요약 정리:
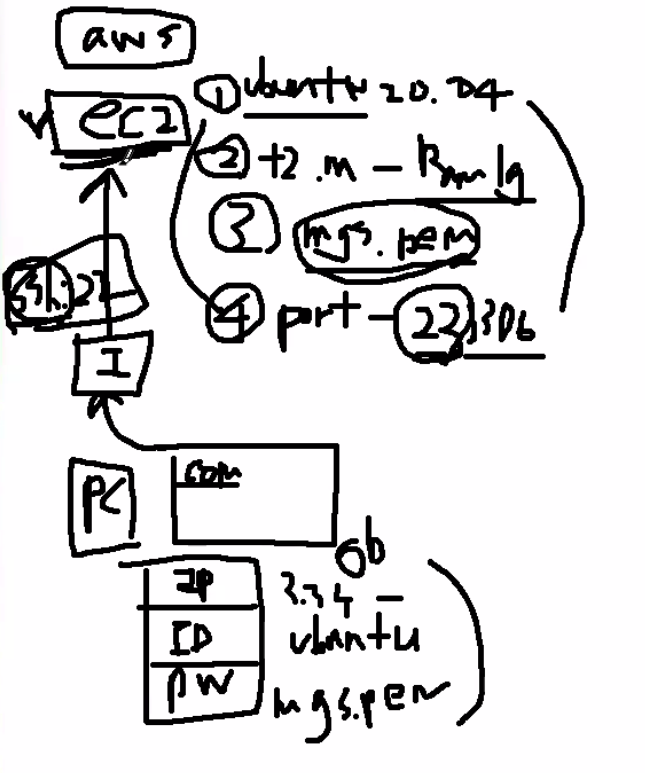
# history 명령어를 사용하여 기존에 입력한 명령어 확인
$ history
1791 ls
1792 history
1793 clear
# !Num 을 사용하여 명령어 다시 사용하기
$ !1793 (엔터!)
$ clear


# SQL Query
# DML : DATA (Like pandas) : CRUD
# DDL : DATABASE, TABLE : CRUD
# DCL : SYSTEM
# DDL : READ
# show databases : show tables
# DML : READ : select from
# select * from country
# select code, name from country
# as : alias : change column name
# operator : 산술, 비교, 논리
# 지난 주에 여기까지 학습!!
# where : 특정 조건으로 데이터를 검색할 때 사용
# where > 산술, 비교, 논리 연산자 사용 가능
USE world;
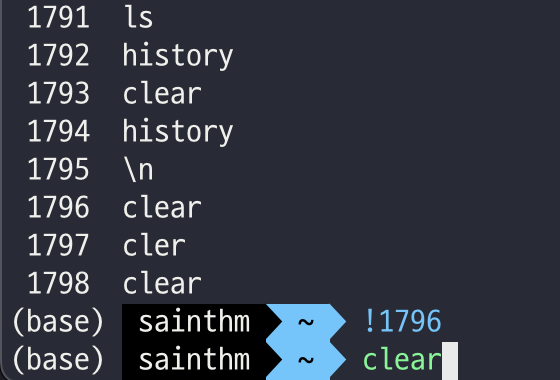
SELECT code, population, population >= 1000 * 10000
FROM country;
#
SELECT code, population
from country
where population >= 10000 * 10000;

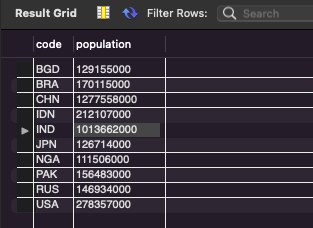
# 국가의 구수가 8천만 ~ 1억인 국가의 국가코드, 국가이름, 인구수 출력
SELECT code, name, population
FROM country
where(population >= 8000*10000) and (population <= 10000*10000);

# between and
SELECT code, name, population
FROM country
WHERE population BETWEEN 8000*10000 and 10000*10000;

# 기존의 OR 방식
# asia, africa 대륙의 국가코드, 국가이름, 대륙이름 출력
SELECT code, name, continent
FROM country
WHERE (continent = "asia") OR (continent = "africa");
# in, not in
# asia, africa 대륙의 국가코드, 국가이름, 대륙이름 출력
SELECT code, name, continent
FROM country
WHERE continent IN ("asia", "africa");
# asia, africa를 제외한 국가 출력
SELECT code, name, continent
FROM country
WHERE continent NOT IN ("asia", "africa");

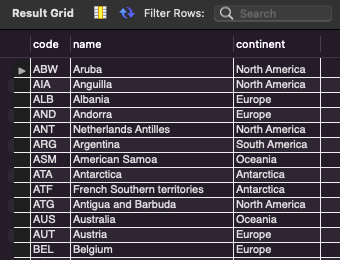
# like : 특정 문자열 포함된 데이터 출력 : df.str.contains("keyword")
# 국가코드가 K로 시작하는 국가의 국가코드, 국가이름 출력
# % : 아무 문자 0개 이상
SELECT code, name
FROM country
WHERE code LIKE "K%"

# order by : asc, desc
# 국가의 인구수가 많은 순으로 정렬해서 국가코드, 인구수 출력
SELECT code, population
FROM country
ORDER BY population DESC;

# limit : 조회하는 데이터의 수를 제한해서 출력
# 인구수가 많은 5개의 국가를 출력 : 인구수 내림차순 > 상위 5개만 출력
SELECT code, population
FROM country
ORDER BY population DESC
limit 5;
# 인구수 상위 5위 ~ 7위까지 출력: 상위 4개 스킵 > 3개 데이터 출력
# limit <skip>, <limit>
SELECT code, population
FROM country
ORDER BY population DESC
LIMIT 4, 3;


지금까지 학습한 사항!
- DML : READ : select, from, where, order by, limit
- operator : 산술, 비교, 논리
- where : between and, in, not in, like
앞으로 학습할 내용!
# DDL: CREATE : create
# Table : 필드명, 데이터타입, 제약조건
# 데이터타입
# 숫자 : int, float
# 문자열 : char, varchar, text
# 날짜시간 : date, time, datetime, timestamp, year
# 제약조건1. Datatype
Reference URL: https://dev.mysql.com/doc/refman/5.7/en/data-types.html
MySQL :: MySQL 5.7 Reference Manual :: 11 Data Types
MySQL supports SQL data types in several categories: numeric types, date and time types, string (character and byte) types, spatial types, and the JSON data type. This chapter provides an overview and more detailed description of the properties of the type
dev.mysql.com
- 데이터 타입은 컴퓨터의 자원을 효율적으로 사용하기 위해 사용되는 방법입니다.
- 많이 사용되는 데이터 타 입의 종류는 숫자형, 문자형, 날짜형 등이 있습니다.
- 저장할 데이터의 타입을 지정하면 저장공간의 할당을 효율적으로 할수 있어 DBMS의 성능을 증가 시킬수 있는 장점이 있습니다.
Numberic:
Reference URL: https://dev.mysql.com/doc/refman/5.7/en/numeric-types.html
MySQL :: MySQL 5.7 Reference Manual :: 11.1 Numeric Data Types
MySQL supports all standard SQL numeric data types. These types include the exact numeric data types (INTEGER, SMALLINT, DECIMAL, and NUMERIC), as well as the approximate numeric data types (FLOAT, REAL, and DOUBLE PRECISION). The keyword INT is a synonym
dev.mysql.com
Integer types(정수 타입):
Reference URL: https://dev.mysql.com/doc/refman/5.7/en/integer-types.html
MySQL :: MySQL 5.7 Reference Manual :: 11.1.2 Integer Types (Exact Value) - INTEGER, INT, SMALLINT, TINYINT, MEDIUMINT,
11.1.2 Integer Types (Exact Value) - INTEGER, INT, SMALLINT, TINYINT, MEDIUMINT, BIGINT MySQL supports the SQL standard integer types INTEGER (or INT) and SMALLINT. As an extension to the standard, MySQL also supports the integer types TINYINT, MEDIUMINT,
dev.mysql.com

# TINYINT 테이블을 생성해서 해당 범위의 값이 들어가는지 확인합니다.
CREATE TABLE number1(
data TINYINT
);
# 지정된 데이터 타입이 표현할수 있는 숫자의 범위를 벗어났기 때문에 데이터가 입력되지 않습니다.
INSERT INTI number1
VALUE (128);
# Unsigned 조건을 추가하면 0 ~ 255까지의 숫자를 입력할수 있습니다.
CREATE TABLE number2(
data TINYINT UNSIGNED
);
INSERT INTI number2
VALUE (128);
# 테이블의 컬럼에 어느정도 범위로 데이터가 들어가는지 확인을 해서 컬럼의 데이터 타입을 결정해야 합니다.
cf) 리스트와 튜플의 저장 데이터 공간 차이 확인!

CHAR & VARCHAR:
- CHAR : 고정길이 문자열 데이터 타입으로 255(2^8)자 까지 입력이 가능
- VARCHAR : 가변길이 문자열 데이터 타입으로 65535(2^16)자 까지 입력이 가능

# CHAR 데이터 타입이 들어간 테이블 생성
CREATE TABLE str1(
data CHAR(255) # 256 이상으로 설정하면 테이블이 생성되지 않습니다.
);
# 데이터 입력
INSERT INTO str1
VALUE ("문자열 입력”);
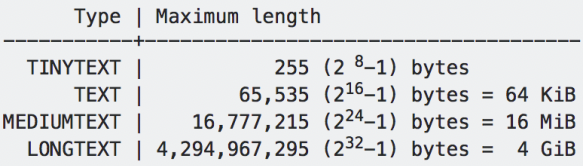
TEXT:
- CHAR와 VARCHAR는 대체로 크기가 작은 문자열을 저장할때 사용되며 크기가 큰 문자열을 저장할 때 는 TEXT 데이터 타입을 사용합니다.
- TEXT의 타입에 따라서 아래와 같이 크기를 가집니다.
Date & Time:
Reference URL: https://dev.mysql.com/doc/refman/5.7/en/date-and-time-types.html
MySQL :: MySQL 5.7 Reference Manual :: 11.2 Date and Time Data Types
11.2 Date and Time Data Types The date and time data types for representing temporal values are DATE, TIME, DATETIME, TIMESTAMP, and YEAR. Each temporal type has a range of valid values, as well as a “zero” value that may be used when you specify an i
dev.mysql.com
DATETIME:
DATETIME은 날짜와 시간을 저장하는 데이터 타입이며, 기본 포멧은 "년-월-일 시:분:초" 입니다.
TIMESTAMP:
TIMESTAMP는 날짜와 시간을 저장하는 데이터 타입이며, DATETI
# Table 확인
DESC city;

제약조건:
# 제약조건
# not null : null 값 저장 X
# unique : 중복값 저장 X
# primary key : not null & unique 제약조건을 동시에 가짐! :
# 테이블 당 하나를 가짐 : row를 구별해주는 역할!
# default : 데이터가 넘오지 않으면 저장되는 데이터 설정 (like python default parameter)
# auto_increment : 자동으로 1씩 증가시켜서 데이터 저장
# foreign key : 데이터의 무결성을 지킴
데이터베이스 생성:
# DDL : CREATE : create
# 데이터베이스 생성
CREATE DATABASE test_sainthm;
# 테이블 생성 : 필드, 데이터타입, 제약조건
SELECT DATABASE(); # 사용중인 데이터베이스 확인 명령어
USE test_sainthm;
CREATE TABLE user(
user_id INT PRIMARY KEY AUTO_INCREMENT
, name VARCHAR(20) NOT NULL
, email VARCHAR(30) UNIQUE NOT NULL
, age INT DEFAULT 30
, rdate TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
DESC user;

# DDL : UPDATE : alter
# 데이터베이스 인코딩 방식 수정
SHOW VARIABLES LIKE "character_set_database";
# dataframe to excel : encoding="utf-8-sig"
ALTER DATABASE test_sainthm CHARACTER SET = ascii;
# 인코딩 확인
SHOW VARIABLES LIKE "character_set_database";


# 테이블 속성값 수정 (3가지 방법으로 가능)
# ADD(필드추가), MODIFY(필드수정),DROP(필드삭제)
# 기존 user 테이블 스키마 확인!
DESC user; # user 테이블 스키마 출력
# 필드 추가 : ADD
ALTER TABLE user ADD content TEXT NOT NULL; # 필드명, 데이터타입, 제약조건 순으로 작성!
# DESC user;
# 필드 수정 : Modify column
ALTER TABLE user MODIFY COLUMN content VARCHAR(100) NOT NULL DEFAULLT "nodata";
# DESC user;
# 필드 삭제 : drop
ALTER TABLE user DROP content;
# DESC user;




# DDL : DELETE : drop
CREATE DATABASE tmp;
USE tmp;
CREATE TABLE test_tmp(
test_id int);
SHOW TABLES;
# 테이블 삭제
DROP TABLE test_tmp;
SHOW TABLES;
# 데이터베이스 삭제
DROP DATABASE tmp;
SHOW DATABASES;



지금까지 배운 SQL 구문 정리!
- DML : READ : select from where order by limit
- DDL : CREATE : create database, create table(field name, dt, con)
- DDL: READ : show, desc
- DDL : UPDATE : alter
- DDL : DELETE : drop
cf) 꿀팁 명령어 정리:
# free 명령어를 통해 메모리 사용량 확인!
free -h
ubuntu@ip-10-0-0-50:~$ free -h
total used free shared buff/cache available
Mem: 966Mi 550Mi 71Mi 1.0Mi 344Mi 271Mi
Swap: 0B 0B 0B
ubuntu@ip-10-0-0-50:~$ sudo systemctl stop mysql
ubuntu@ip-10-0-0-50:~$ free -h
total used free shared buff/cache available
Mem: 966Mi 212Mi 408Mi 1.0Mi 344Mi 609Mi
Swap: 0B 0B 0B
ubuntu@ip-10-0-0-50:~$ sudo systemctl start mysql
ubuntu@ip-10-0-0-50:~$ free -h
total used free shared buff/cache available
Mem: 966Mi 525Mi 61Mi 1.0Mi 379Mi 296Mi
Swap: 0B 0B 0B
# DML : CREATE
use test_sainthm;
SHOW TABLES;
DESC user;
SELECT * FROM user;
INSERT INTO user(name, email, age)
values("andy", "andy@gmail.com", 23)
, ("john", "john@gmail.com", 42)
, ("peter", "peter@naver.com", 37)
, ("alice", "alice@naver.com", 17)
, ("anchel", "anchel@naver.com", 35);
SELECT * FROM user;
# user 추가 (나이없이 추가해보기!)
INSERT INTO user(name, email)
values("po", "po@gmail.com");
# default 나이로 설정한 30세 값이 들어감!
SELECT user_id, name
FROM user
where age >= 30;





# select로 출력된 결과 테이블에 저장
CREATE TABLE backup(
user_id INT
, name VARCHAR(20)
);
DESC backup;
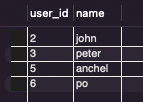
SELECT * FROM user;
INSERT INTO backup
SELECT user_id, name
FROM user
where age >= 30;
SELECT * FROM backup
# DML : UPDATE : update set
SELECT * FROM user;
# 29세 이하는 나이를 20세로 변경
UPDATE user
SET age = 20
WHERE age < 30
LIMIT 5;
SELECT * FROM user;


UPDATE user
SET name="jin", email="jin@gmail.com"
where name="po"
limit 1;
SELECT * FROM user;

# DML : DELETE : delete from
# user의 나이가 30세 미만의 데이터 삭제
SELECT * FROM user;
DELETE FROM user
Where age < 30
LIMIT 2;
#
DELETE FROM user
WHERE age < 30
# 확인
DELETE FROM user
WHERE age < 30
LIMIT 2;


지금까지 배운 SQL 구문 정리!
- DML : DATA : C(insert into), R(select from), U(update set), D(delete from)
- DDL: DATABASE, TABLE : C(create), R(show, desc), U(alter), D(drop)
Foreign key 실습:
# Foreign key: 외래키
# 데이터의 무결성을 지키기 위해서 사용 : unique, primary key 제약조건이 있어야 설정 가능
# 참조해서 데이터를 추가하도록 정의
# 참조값이 없으면 데이터 추가 불가능 > 데이터의 무결성을 지킬 수 있음!!
# 테이블 생성
CREATE TABLE customer(
user_id INT PRIMARY KEY AUTO_INCREMENT
, name VARCHAR(20) NOT NULL
);
CREATE TABLE income(
user_id INT NOT NULL
, amount INT NOT NULL
);
INSERT INTO customer(name)
VALUES ("a"), ("b"), ("c");
SELECT * FROM customer;

INSERT INTO income(user_id, amount)
VALUES (1, 100), (3, 200), (1, 200);
SELECT * FROM income;

# income 테이블 확인
SELECT * FROM income;
# fk 설정 안한상태에서 데이터 추가
insert into income(user_id, amount)
values (4, 400);
select * from income;
# income 테이블 초기화
TRUNCATE income; # 스키마는 유지, 데이터만 삭제
SELECT * FROM income;
DESC income;
ALTER TABLE income
ADD CONSTRAINT user_fk
FOREIGN KEY (user_id)
REFERENCES customer (user_id);
INSERT INTO income(user_id, amount)
VALUES (1, 100), (3, 200), (1, 200);
SELECT * FROM income;
# fk 설정후 데이터 추가
INSERT INTO income(user_id, amount)
VALUES (4, 400);

# 참조된 필드의 데이터 삭제
SELECT * FROM customer;
DELETE FROM customer
WHERE user_id = 3
LIMIT 1;
DROP TABLE customer;
# fk 설정: on update, on delete
# cascade: 동기화
# set null: null 데이터로 변경
# no action: 변경 X
# set default: default 값으로 변경
# restrict: 에러 발생 : 수정, 삭제 불가
# on update: cascade
# on delete: set null
DROP TABLE income;
CREATE TABLE income(
user_id INT
, amount INT NOT NULL
, FOREIGN KEY (user_id) REFERENCES customer(user_id)
ON UPDATE CASCADE ON DELETE SET NULL
);
INSERT INTO income(user_id, amount)
VALUES (1, 100), (3, 200), (1, 200);
SELECT * FROM income;
DESC income;
SELECT * FROM customer



UPDATE customer
SET user_id = 4
WHERE user_id = 3
LIMIT 1;
SELECT * FROM customer;
SELECT * FROM income;

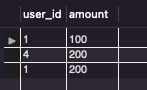
SELECT * FROM customer;
# 삭제 테스트
DELETE FROM customer
WHERE user_id = 4
limit 1;
SELECT * FROM customer;
SELECT * FROM income;



Function:
- round
- concat
- count
- distinct
- date_format
# Function 실습:
SELECT round(12.345);
> 12
SELECT round(12.345, 2);
> 12.35
# concat : 국가이름(국가코드) 가 출력되는 컬럼을 생성
USE world;
SELECT code, name, concat(name, "(", code, ")") as name_code
FROM country;

# count
SELECT count(*)
FROM country;
> 239
# 동일한 표현
# SELECT COUNT(*) FROM country;
# SELECT COUNT(code) FROM country;
# distinct: 중복데이터 제거
# 전체 대륙의 종류의 개수를 출력: 중복되는 대륙 제거(distinct) > 데이터의 개수 출력(count())
SELECT continent
FROM country;
SELECT count(distinct(continent))
FROM country;


# date_format: 날짜시간 데이터의 모양을 변경 : 년월일 시분초 > 년월
USE sakila;
SELECT * FROM payment;
# 매출이 발생한 년월을 출력 : 매출 데이터를 년월 데이터로 변경(date_format) > 중복데이터 제거(distinct)
SELECT payment_date
FROM payment;
SELECT distinct(date_format(payment_date, "%Y-%m"))
FROM payment;
date_format Reference URL: https://dev.mysql.com/doc/refman/5.7/en/date-and-time-functions.html
MySQL :: MySQL 5.7 Reference Manual :: 12.7 Date and Time Functions
12.7 Date and Time Functions This section describes the functions that can be used to manipulate temporal values. See Section 11.2, “Date and Time Data Types”, for a description of the range of values each date and time type has and the valid formats
dev.mysql.com





# group by : 특정컬럼(중복결합), 다른컬럼(결합함수) > 데이터 출력
# 결합함수 : min, max, avg, sum, count ...
# 어떤 스태프가 더 많은 매출을 올렸을까?
SELECT *
FROM payment;
SELECT staff_id, sum(amount)
FROM payment
GROUP by staff_id;
#
SELECT staff_id, sum(amount), count(amount), sum(amount) / count(amount)
FROM payment
GROUP by staff_id;

'AI > [부트캠프] 데이터 사이언티스트 과정' 카테고리의 다른 글
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 22. (2) | 2022.09.22 |
|---|---|
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 20. (0) | 2022.09.20 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 18. (2) | 2022.09.16 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 14. (0) | 2022.09.08 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 13. (0) | 2022.09.07 |