
안녕하세요 늑대양입니다 :)
오늘은 [AI 데이터 사이언티스트 취업 완성 과정]의 13일차 일과를 정리하여 안내해드리도록 하겠습니다.

Day 13. 시간표:
- 온라인 강의: [웹크롤링 기초 : Python]
- 오프라인 강의: [웹크롤링 실전 : Python]
Day 13. 온라인 학습 범위:
- 19강
- 예상 학습 시간: 4:01:43
| 대주제(Part) | 중주제(Chapter) | 소주제(Clip) |
| Part 1. 준비 단계 | Ch 00. 인트로 | 01. 강의 및 강사 소개, 동기부여, 개요 |
| Part 1. 준비 단계 | Ch 01. 업무 자동화를 위해 컴퓨터를 세팅합니다 | 01. 코드 다운로드 및 개발 환경 설치 (파이썬, 파이참, 깃) |
| Part 2. 파이썬 기초 문법과 함수 | Ch 02. 파이썬 겉핥기! 필요한 만큼만 알려드립니다 | 01. 인터프레터와 대화하기, 기초 연산, 변수 - 1 |
| Part 2. 파이썬 기초 문법과 함수 | Ch 02. 파이썬 겉핥기! 필요한 만큼만 알려드립니다 | 01. 인터프레터와 대화하기, 기초 연산, 변수 - 2 |
| Part 2. 파이썬 기초 문법과 함수 | Ch 02. 파이썬 겉핥기! 필요한 만큼만 알려드립니다 | 02. 순서가 중요한 데이터들 |
| Part 2. 파이썬 기초 문법과 함수 | Ch 02. 파이썬 겉핥기! 필요한 만큼만 알려드립니다 | 03. 논리를 서술하는 도구 |
| Part 2. 파이썬 기초 문법과 함수 | Ch 02. 파이썬 겉핥기! 필요한 만큼만 알려드립니다 | 04. 함수와 클래스 |
| PART 6. 인터넷 자동화 | Ch 24. 크롤러! 인터넷 탐색을 자동화합니다. | 01. 크롤러, 컴퓨터 세팅 및 셀레늄(Selenium) 겉핥기 (실습) |
| PART 6. 인터넷 자동화 | Ch 28. 크롤링에 필요한 HTML 지식 15분만에 알려드립니다 | 01. 웹페이지 뜯어보기, 유튜브 조회수 조작, 가짜뉴스 제작 |
| PART 6. 인터넷 자동화 | Ch 29. 최신 뉴스 기사를 트위터에 자동으로 스크랩해 봅니다 | 01. 코드 실행 과정 살펴보기, main.py 코드 살펴보기, 구글 뉴스 검색 쿼리, 웹 요소 |
| PART 6. 인터넷 자동화 | Ch 29. 최신 뉴스 기사를 트위터에 자동으로 스크랩해 봅니다 | 02. 웹페이지 요소를 찾아라! find_element 함수 시리즈 살펴보기 |
| PART 6. 인터넷 자동화 | Ch 29. 최신 뉴스 기사를 트위터에 자동으로 스크랩해 봅니다 | 03. 구글 뉴스 검색 결과 크롤링! find_element 함수 응용하기 |
| PART 6. 인터넷 자동화 | Ch 29. 최신 뉴스 기사를 트위터에 자동으로 스크랩해 봅니다 | 04. 트위터 게시물 작성 요소 크롤링 전략, 알고리즘 순서도 |
| PART 6. 인터넷 자동화 | Ch 30. 크롤러를 비즈니스에 활용해도 되나요 | 01. 크롤러의 비즈니스 활용, 법적 이슈 |
| PART 6. 인터넷 자동화 | Ch 31. 인스타그램에서 사진을 크롤링합니다 | 01. 코드 실행과정 살펴보기, main.py 코드 살펴보기, 로그인 요소 크롤링 |
| PART 6. 인터넷 자동화 | Ch 31. 인스타그램에서 사진을 크롤링합니다 | 02. 인스타그램 태그 검색, 최근 게시물 크롤링, 게시물 스크린샷, 다음 버튼 요소 크롤링 |
| PART 6. 인터넷 자동화 | Ch 31. 인스타그램에서 사진을 크롤링합니다 | 03. 알고리즘 순서도, 헤드리스 모드로 크롤러를 실행하는 방법 |
| PART 6. 인터넷 자동화 | Ch 32. 인스타그램에서 고객 리뷰를 자동으로 관리합니다 | 01. 코드 실행과정 살펴보기, main.py 코드 살펴보기, 좋아요 버튼 요소 크롤링, 이미 좋아요 누른 게시물 건너뛰기 |
| PART 6. 인터넷 자동화 | Ch 32. 인스타그램에서 고객 리뷰를 자동으로 관리합니다 | 02. 코드 실행하기, 댓글 창 요소 크롤링, 댓글 자동으로 달기 |
Day 13. 웹크롤링 실전 : Python
네이버 영화 클레멘타인 평점 크롤링:
# 필요한 라이브러리 가져오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import requests
import json
import time
from pandas.io.json import json_normalize
from bs4 import BeautifulSoup
# 1. 숨은 url 설정 및 헤더 정보 정의
# CODE
url = "https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=37886&type=after&onlyActualPointYn=N&onlySpoilerPointYn=N&order=sympathyScore"
header = {
"referer" : "https://movie.naver.com/movie/bi/mi/point.naver?code=37886",
"user-agent" : "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Mobile Safari/537.36"
}
# 2. resp 변수명으로 requests로 url 요청한 데이터의 text를 저장합니다.
# CODE
resp = requests.get(url)
# 3. resp 결과값 앞 1000글자 확인 및 어떤형태의 데이터인지 파악하기
# CODE
resp.text[:1001] # str, html
>'\r\n\r\n\r\n\r\n<!DOCTYPE html>\r\n<html lang="ko">\r\n<head>\r\n\t<meta charset="utf-8">\r\n\t<meta http-equiv="X-UA-Compatible" content="IE=edge">\r\n\t<title>네이버 영화</title>\r\n\t\n\n\n\t\n\t\n\t\n\t\n\t\t<link rel="shortcut icon" href="https://ssl.pstatic.net/static/m/movie/icons/naver_movie_favicon.ico" type="image/x-icon">\n\t\t\t\n\n\r\n\t\n<link rel="stylesheet" type="text/css" href="/css/common.css?20220823121742" />\r\n\t\n<link rel="stylesheet" type="text/css" href="/css/movie_tablet.css?20220823121742" />\n<link rel="stylesheet" type="text/css" href="/css/movie_end.css?20220823121742" />\r\n\t\r\n\t\n\n\n<script type="text/javascript" src="/js/deploy/movie.all.js?20220823121742"></script>\n\n\n\r\n</head>\r\n<body>\r\n\t<!-- content -->\r\n<input type="hidden" name="movieCode" id="movieCode" value="37886"/>\r\n<input type="hidden" name="onlyActualPointYn" id="onlyActualPointYn" value="N"/>\r\n<input type="hidden" name="includeSpoilerYn" id="includeSpoilerYn" value="N"/>\r\n<input type="hidden" name="order" id="order" value="sympathyScore"/>\r\n<input type'
# 4. response 결과에 따라 적절한 변환 함수를 사용하여 data라는 변수명에 저장합니다.
# CODE
resp = requests.get(url, headers=header)
html = BeautifulSoup(resp.text, 'html.parser')
# 5. 전설적인 댓글평점 '이 영화를 보고 암이 나았습니다.' 에 selector를 사용하여 접근해봅시다.
# CODE
# #_filtered_ment_0
# data
# data.select('p')[4]
html.select('p span')[0]
><span id="_filtered_ment_0">
이 영화를 보고 암이 나았습니다.
</span>
# 6. selector로 선택한 항목에서 텍스트만을 추려봅시다.
html.select('span#_filtered_ment_0')[0].text.strip()
>'이 영화를 보고 암이 나았습니다.'
# 7. 1페이지의 모든 숫자평점과, 댓글평점을 프린트해 봅시다.
# CODE
html.select('div.star_score em')
>[<em>10</em>,
<em>1</em>,
<em>10</em>,
<em>10</em>,
<em>10</em>,
<em>10</em>,
<em>10</em>,
<em>10</em>,
<em>10</em>,
<em>10</em>]
for i in range(10):
print(html.select('div.star_score em')[i].text, html.select(f'span#_filtered_ment_{i}')[0].text.strip())
>10 이 영화를 보고 암이 나았습니다.
1 이것은절대1점이아니다11점을주고싶은 내마음이다
10 모니터도 울고 외장하드도 울고 숨어있던 바이러스도 울었다
10 당신이 이 영화를 보지 않았다면 아직 살아있을 이유 하나를 간직하고 있는 것이다.
10 영화계엔 BC와 AC가 있다. Before Clementain, After Clementain...
10 남친 집에서 클레멘타인 DVD를 발견했고, 결혼을 결심했습니다.
10 드디어 보았네요. 나이 40대 중반에 이런 감동을 느낄 수 있음에 스스로도 대견한 생각이 듭니다. 먼 훗날 제 아이들도 이 영화를 보고 저와 같은 감동을 느끼길 바라는 건 그저 바램이겠지요?
10 평점깍아내리는 낚시글 몇개있는데 제발그만해라 이기적인새끼들아좋은건 나누는거다
10 장난으로 쓰지마라... 본인은 2004년에 실제로 극장에서 이 영화를 봤다
10 프로포즈 선물로 다이아반지 대신 클레멘타인 파일을 USB에담아 목걸이로 만들어 그녀 목에 걸어주었다. 눈물로 대신 대답한 그녀...그리고 2세이름은 그녀의 의견을 반영해 이동준과 스티븐시갈의 이름을 딴 이동갈로 지을...
# 8. 네이버에서는 기계적으로 접근하는 요청을 잘 차단합니다. 지난시간 차단을 막는 코드를 포함하여 1~10페이지의 평점과 댓글평점을 크롤링하여 데이터프레임으로 저장하세요
# CODE
# 저장할 데이터프레임과 리스트 생성
data_list = []
# 반복문을 사용하여 페이지 URL 생성
for page in range(1, 11):
print(f"{page} 페이지 정상처리")
url = f"https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=37886&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page={page}"
# print(url)
# 난수를 생성하여 차단 피하기
# requests 요청 전에 실행되도록 위치합니다.
randn = np.random.randint(100)
np.random.seed(randn)
time_sleep = np.random.randint(1, 5)
time.sleep(time_sleep)
# url 요청
resp = requests.get(url, headers=header)
resp.text
# 데이터 파싱
html = BeautifulSoup(resp.text, 'html.parser')
# 반복문을 사용하여 리스트에 추출정보를 저장
for i in range(10):
data_list.append(html.select('div.star_score em')[i].text)
data_list.append(html.select(f'span#_filtered_ment_{i}')[0].text.strip())
# 리스트정보를 데이터프레임에 저장
data = np.array(data_list).reshape(-1, 2)
df = pd.DataFrame(data,
columns=['star score', 'reply'])
>1 페이지 정상처리
2 페이지 정상처리
3 페이지 정상처리
4 페이지 정상처리
5 페이지 정상처리
6 페이지 정상처리
7 페이지 정상처리
8 페이지 정상처리
9 페이지 정상처리
10 페이지 정상처리
df
>
star score reply
0 10 이 영화를 보고 암이 나았습니다.
1 1 이것은절대1점이아니다11점을주고싶은 내마음이다
2 10 모니터도 울고 외장하드도 울고 숨어있던 바이러스도 울었다
3 10 당신이 이 영화를 보지 않았다면 아직 살아있을 이유 하나를 간직하고 있는 것이다.
4 10 영화계엔 BC와 AC가 있다. Before Clementain, After Clem...
... ... ...
95 9 너무 장난스럽게 그러면 이 영화에 대한 신빙성이 떨어지죠. 10점은 말도 안되고 9...
96 10 도대체 3D 블루레이 버전은 언제나오나요... 기금모금이라도 하고 싶습니다.
97 10 1분이 1초 같아요
98 10 이영화를 보고나서 아버지 방으로가서 주무시고 계시는 아버지의 얼굴을 물끄러미 쳐다봤...
99 10 밑의 분 너무하시네요. 이런 명작을 폄하하시다니, 이 영화를 보신적이 있으시기나 한...
100 rows × 2 columns
Naver Developers:
Naver Developers 메인 URL: https://developers.naver.com/main/
NAVER Developers
네이버 오픈 API들을 활용해 개발자들이 다양한 애플리케이션을 개발할 수 있도록 API 가이드와 SDK를 제공합니다. 제공중인 오픈 API에는 네이버 로그인, 검색, 단축URL, 캡차를 비롯 기계번역, 음
developers.naver.com


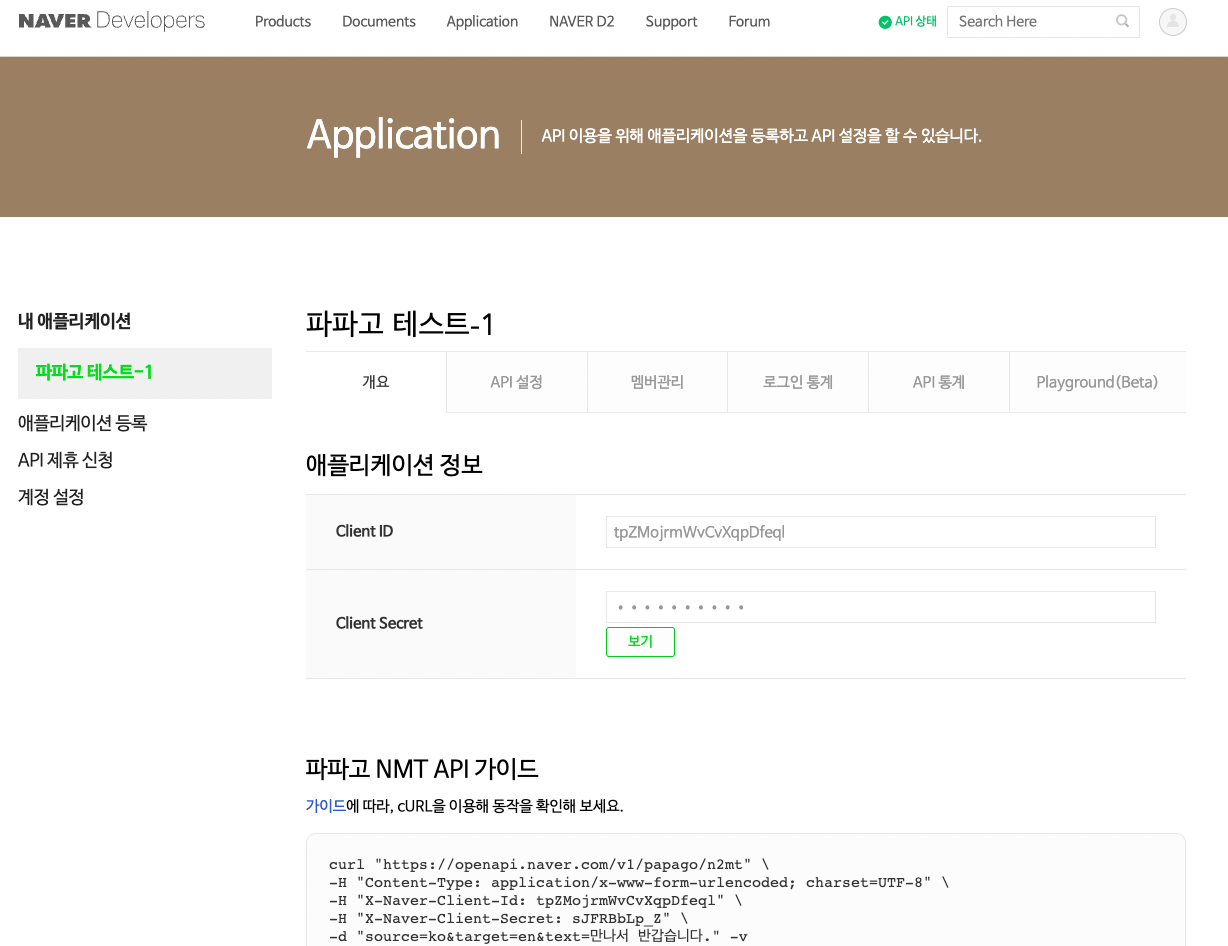
네이퍼 파파고 API:

# 애플리케이션 정보
app_id = "tpZMojrmWvCvXqpDfeql"
app_pw = "*******" # 애플리케이션 정보의 시크릿값 입력
#
url = "https://openapi.naver.com/v1/papago/n2mt"
header = {
"Content-Type" : "application/x-www-form-urlencoded; charset=UTF-8",
"X-Naver-Client-Id" : app_id,
"X-Naver-Client-Secret" : app_pw
}
data = {
"source" : "ko",
"target" : "en",
"text" : input("영어로 번역할 한국어를 입력해주세요 : ")
}
>영어로 번역할 한국어를 입력해주세요 : 안녕하세요
# 요청방법 get() <---- 헤더정보를 포함해서 요청할 경우!!
# 요청방법 post() <---- 헤더정보와 데이터를 포함해서 요청할 경우!! (값을 업데이트 한다던지, 지금처럼 작업 데이터가 있는 경우)
resp = requests.post(url, headers=header, data=data)
resp.text
>'{"message":{"result":{"srcLangType":"ko","tarLangType":"en","translatedText":"Hello","engineType":"PRETRANS","pivot":null,"dict":null,"tarDict":null},"@type":"response","@service":"naverservice.nmt.proxy","@version":"1.0.0"}}'
# json 데이터 로드!
json_data = json.loads(resp.text)
json_data
>{'message': {'result': {'srcLangType': 'ko',
'tarLangType': 'en',
'translatedText': 'Hello',
'engineType': 'PRETRANS',
'pivot': None,
'dict': None,
'tarDict': None},
'@type': 'response',
'@service': 'naverservice.nmt.proxy',
'@version': '1.0.0'}}
# json data 결과 출력물!
json_data['message']['result']['translatedText']
>'Hello'
# papage api 활용!
url = "https://openapi.naver.com/v1/papago/n2mt"
header = {
"Content-Type" : "application/x-www-form-urlencoded; charset=UTF-8",
"X-Naver-Client-Id" : app_id,
"X-Naver-Client-Secret" : app_pw
}
data = {
"source" : "ko",
"target" : "en",
"text" : input("영어로 번역할 한국어를 입력해주세요 : ")
}
resp = requests.post(url, headers=header, data=data)
resp.text
json_data = json.loads(resp.text)
json_data['message']['result']['translatedText']
>영어로 번역할 한국어를 입력해주세요 : 안녕하세요 수강생 여러분 크롤링 재미있나요? 여러분의 재미를 찾아보세요!
'Hello, students. Are you having fun crawling? Find Your Fun!'
# papago() 함수 만들기!
def papago():
x = input('번역이 필요한 영어를 입력하세요 : ')
url = "https://openapi.naver.com/v1/papago/n2mt"
header = {
"Content-Type" : "application/x-www-form-urlencoded; charset=UTF-8",
"X-Naver-Client-Id" : app_id,
"X-Naver-Client-Secret" : app_pw
}
data = {
"source" : "en",
"target" : "ko",
"text" : x
}
resp = requests.post(url, headers=header, data=data)
resp.text
json_data = json.loads(resp.text)
json_data['message']['result']['translatedText']
return json_data['message']['result']['translatedText']
# 함수 실행!
papago()
>번역이 필요한 영어를 입력하세요 : Study hard! It's fun to study!
'공부 열심히 해! 공부하는 것은 재미있어요!'

# jupyter notebook에서 실행
from papago import papago
papago()
>번역이 필요한 영어를 입력하세요 : hi, my name is sainthm
'안녕, 내 이름은 sainthm이야.'
공공데이터 포털:
공공데이터 포털 메인 URL: https://www.data.go.kr/
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr








공공데이터 API 활용:
# 공공데이터 API 활용 예제
# key 값 등록
key1 = "*****************************************" # key 값은 공공데이터 값 사용 encoding
key2 = "*****************************************" # key 값은 공공데이터 값 사용 encoding
# url, header, resp 등록
url = "http://apis.data.go.kr/3130000/openapi/sns/getsns"
header = {
"serviceKey" : key2,
"type" : "Json"
}
resp = requests.get(url, params=header)
# resp 확인
resp
><Response [200]>
# resp.text 확인
resp.text
>'{"resultCode":"0","resultMsg":"SUCCESS","numOfRows":10,"pageNo":0,"totalCount":377,"items":[{"date":"2018-07-01","positive":"2956","negative":"648","neutral":"295","addr":"홍대 걷고 싶은 거리"},{"date":"2018-08-01","positive":"2247","negative":"111","neutral":"200","addr":"홍대 걷고 싶은 거리"},{"date":"2018-09-01","positive":"3602","negative":"635","neutral":"436","addr":"홍대 걷고 싶은 거리"},{"date":"2018-10-01","positive":"2827","negative":"394","neutral":"623","addr":"홍대 걷고 싶은 거리"},{"date":"2018-11-01","positive":"2004","negative":"356","neutral":"583","addr":"홍대 걷고 싶은 거리"},{"date":"2018-12-01","positive":"1457","negative":"223","neutral":"173","addr":"홍대 걷고 싶은 거리"},{"date":"2019-01-01","positive":"1444","negative":"143","neutral":"127","addr":"홍대 걷고 싶은 거리"},{"date":"2019-02-01","positive":"6886","negative":"215","neutral":"220","addr":"홍대 걷고 싶은 거리"},{"date":"2019-03-01","positive":"1945","negative":"175","neutral":"160","addr":"홍대 걷고 싶은 거리"},{"date":"2019-04-01","positive":"1773","negative":"90","neutral":"103","addr":"홍대 걷고 싶은 거리"}]}'
# json loads() 활용!
data = json.loads(resp.text)
data
>{'resultCode': '0',
'resultMsg': 'SUCCESS',
'numOfRows': 10,
'pageNo': 0,
'totalCount': 377,
'items': [{'date': '2018-07-01',
'positive': '2956',
'negative': '648',
'neutral': '295',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-08-01',
'positive': '2247',
'negative': '111',
'neutral': '200',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-09-01',
'positive': '3602',
'negative': '635',
'neutral': '436',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-10-01',
'positive': '2827',
'negative': '394',
'neutral': '623',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-11-01',
'positive': '2004',
'negative': '356',
'neutral': '583',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-12-01',
'positive': '1457',
'negative': '223',
'neutral': '173',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2019-01-01',
'positive': '1444',
'negative': '143',
'neutral': '127',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2019-02-01',
'positive': '6886',
'negative': '215',
'neutral': '220',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2019-03-01',
'positive': '1945',
'negative': '175',
'neutral': '160',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2019-04-01',
'positive': '1773',
'negative': '90',
'neutral': '103',
'addr': '홍대 걷고 싶은 거리'}]}
# items 항목 확인
data['items']
>[{'date': '2018-07-01',
'positive': '2956',
'negative': '648',
'neutral': '295',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-08-01',
'positive': '2247',
'negative': '111',
'neutral': '200',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-09-01',
'positive': '3602',
'negative': '635',
'neutral': '436',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-10-01',
'positive': '2827',
'negative': '394',
'neutral': '623',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-11-01',
'positive': '2004',
'negative': '356',
'neutral': '583',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2018-12-01',
'positive': '1457',
'negative': '223',
'neutral': '173',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2019-01-01',
'positive': '1444',
'negative': '143',
'neutral': '127',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2019-02-01',
'positive': '6886',
'negative': '215',
'neutral': '220',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2019-03-01',
'positive': '1945',
'negative': '175',
'neutral': '160',
'addr': '홍대 걷고 싶은 거리'},
{'date': '2019-04-01',
'positive': '1773',
'negative': '90',
'neutral': '103',
'addr': '홍대 걷고 싶은 거리'}]
# DataFrame 활용
df = pd.DataFrame(data['items'])
df
>
date positive negative neutral addr
0 2018-07-01 2956 648 295 홍대 걷고 싶은 거리
1 2018-08-01 2247 111 200 홍대 걷고 싶은 거리
2 2018-09-01 3602 635 436 홍대 걷고 싶은 거리
3 2018-10-01 2827 394 623 홍대 걷고 싶은 거리
4 2018-11-01 2004 356 583 홍대 걷고 싶은 거리
5 2018-12-01 1457 223 173 홍대 걷고 싶은 거리
6 2019-01-01 1444 143 127 홍대 걷고 싶은 거리
7 2019-02-01 6886 215 220 홍대 걷고 싶은 거리
8 2019-03-01 1945 175 160 홍대 걷고 싶은 거리
9 2019-04-01 1773 90 103 홍대 걷고 싶은 거리
# REST API 방식
url = "http://apis.data.go.kr/3130000/openapi/sns/getsns?serviceKey=<*****키 값 변경*****>&type=Json"
resp = requests.get(url)
# resp status 코드 확인
resp
><Response [200]>
# resp.text 확인
resp.text
>'{"resultCode":"0","resultMsg":"SUCCESS","numOfRows":10,"pageNo":0,"totalCount":377,"items":[{"date":"2018-07-01","positive":"2956","negative":"648","neutral":"295","addr":"홍대 걷고 싶은 거리"},{"date":"2018-08-01","positive":"2247","negative":"111","neutral":"200","addr":"홍대 걷고 싶은 거리"},{"date":"2018-09-01","positive":"3602","negative":"635","neutral":"436","addr":"홍대 걷고 싶은 거리"},{"date":"2018-10-01","positive":"2827","negative":"394","neutral":"623","addr":"홍대 걷고 싶은 거리"},{"date":"2018-11-01","positive":"2004","negative":"356","neutral":"583","addr":"홍대 걷고 싶은 거리"},{"date":"2018-12-01","positive":"1457","negative":"223","neutral":"173","addr":"홍대 걷고 싶은 거리"},{"date":"2019-01-01","positive":"1444","negative":"143","neutral":"127","addr":"홍대 걷고 싶은 거리"},{"date":"2019-02-01","positive":"6886","negative":"215","neutral":"220","addr":"홍대 걷고 싶은 거리"},{"date":"2019-03-01","positive":"1945","negative":"175","neutral":"160","addr":"홍대 걷고 싶은 거리"},{"date":"2019-04-01","positive":"1773","negative":"90","neutral":"103","addr":"홍대 걷고 싶은 거리"}]}'

긴 글 읽어주셔서 감사합니다 :)
'AI > [부트캠프] 데이터 사이언티스트 과정' 카테고리의 다른 글
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 18. (2) | 2022.09.16 |
|---|---|
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 14. (0) | 2022.09.08 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 12. (0) | 2022.09.06 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 11. (0) | 2022.09.05 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 10. (0) | 2022.09.02 |