
안녕하세요 늑대양입니다 :)
어제는 크롤링 미니프로젝트 발표를 진행했었습니다!
오늘부터 SQL 공부를 시작합니다!!
오늘은 [AI 데이터 사이언티스트 취업 완성 과정]의 18일차 일과를 정리하여 안내해드리도록 하겠습니다.

Day 18 시간표:
- 오프라인 강의: SQL 기초
- 오프라인 강의: SQL 기초
- 선택학습
Day 18. SQL 기초
SQL 기초:
강사님 소개:
- 박두* 강사님
- 마이크로프로세서를 이용한 자동제어
- WLAN, WPAN MAC(Media Access Control) 프로토콜 설계

History:
시지온:
- 국민은행 오픈웹 소셜 댓글 서비스 개발 참여
- 소셜 댓글 서비스 라이브리 풀스택개발
- 댓글 형태소 분석 서비스 풀스택 개발
JLK-Inpection:
- 딥러닝 CNN을 이용한 MRI 3D 이미지 병명 분류 AI 모델 개발 및 서비스화
N3N:
- Wizeye 개발
- 빅데이터를 수집/분석하여 시각화 맵으로 모니터링
Veranos:
- 삼성자산운용 GBI 시뮬레이터 개발
패스트캠퍼스:
- 데이터 사이언스 스쿨
- 웹프로그래밍 스쿨
- 프론트엔드 프로그래밍 스쿨
- 파이썬 데이터 분석 캠프
- 파이썬 웹 크롤링 및 자동화 시스템 구축 캠프
기업강의:
- 만도 AI Engineer 과정
- LG 전자 머신러닝 과정
- 삼성금융연수원 머신러닝 과정
- 현대 모비스 AIM 머신러닝 과정
- SK C&C 데이터 사이언티스트 과정
- KT 미래인재육성 머신러닝 과정
DATABASE:
Index:
- About Database
- Database Classification
- Database Ranking
- MySQL
- RDBMS
About Database:
DB:
- Database
- 데이터를 통합하여 관리하는 데이터의 집합
DBMS:
- Database Management System
- 데이터베이스를 관리하는 미들웨어 시스템을 데이터베이스 관리시스템
RDBMS:
- Relational Database Management System
- Oracle, MySQL, PostgreSQL, Sqlite
- 데이터 테이블 사이에 키값으로 관계를 가지고 있는 데이터베이스
- 데이터 사이의 관계 설정으로 최적화된 스키마를 설계 가능
- MySQL 학습
- 데이터를 읽어올 때 유리
- 데이터를 저장하거나 수정, 삭제할 때, 관계를 갖고 있으므로 데이터 간 영향을 줄 가능성이 있음
- 위의 작업을 할 때 느릴 수 있음
NoSQL:
- MongoDB, HBase, Cassandra
- 데이터 테이블 사이에 관계가 없이 저장하는 데이터베이스
- 데이터를 추가, 수정, 삭제할 때, 속도가 빠름!
- 로그 파일 등을 저장하기에 효율이 좋음
Database Ranking:
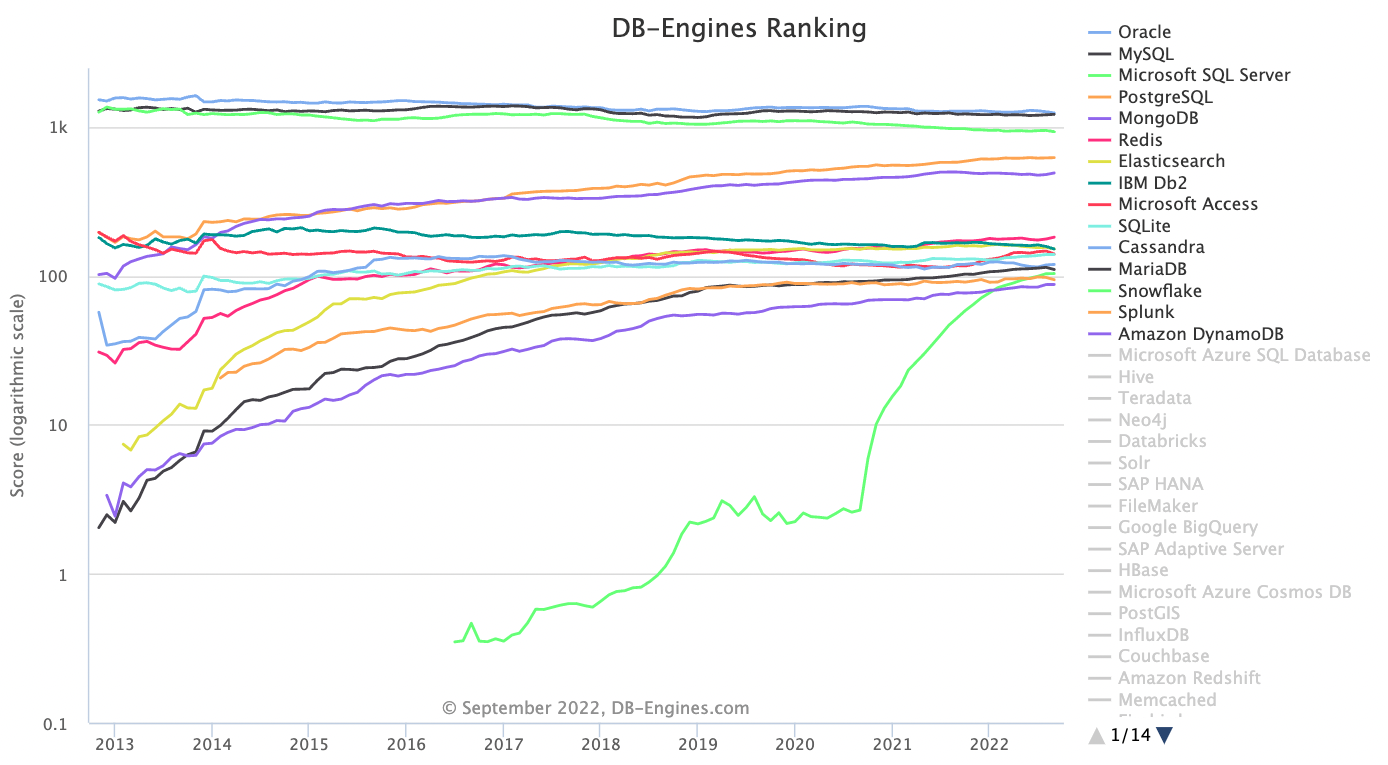
About MySQL:
Feature:
- MySQL은 오픈소스이며, 다중 사용자와 다중 스레드 지원
- 다양한 운영체제에 다양한 프로그래밍 언어 지원
- 표준 SQL을 사용
- 세계적으로 많이 사용
- 작고 강력하며 가격이 저렴
- cf) Oracle pricing table: https://www.oracle.com/us/corporate/pricing/technology-price-list-070617.pdf
History:
- 1995 - MySQL AB사에 의해 첫 버전 발표
- 2008 - 썬 마이크로시스템이 MySQL AB 인수, 5.1 버전 발표
- 2009 - 오라클이 썬 마이크로시스템 인수
- 2017 - 5.7.20
- 2022 - 8.0.30 (최신버전)
License:
- MySQL을 포함하는 하드웨어나 소프트웨어 기타 장비를 판매하는 경우 라이센스 필요
- 배포시 소스를 공개하면 무료이지만 소스공개를 원하지 않는 경우 상용 라이센스 필요
- 서비스에 이용하는 것은 무료로 가능
RDBMS:

Feature:
- 데이터 분류, 정렬, 탐색속도가 빠름
- 오래 사용된 만큼 신뢰성이 높음
- 스키마(데이터의 구조) 수정이 어려움
Structure:

Schema:
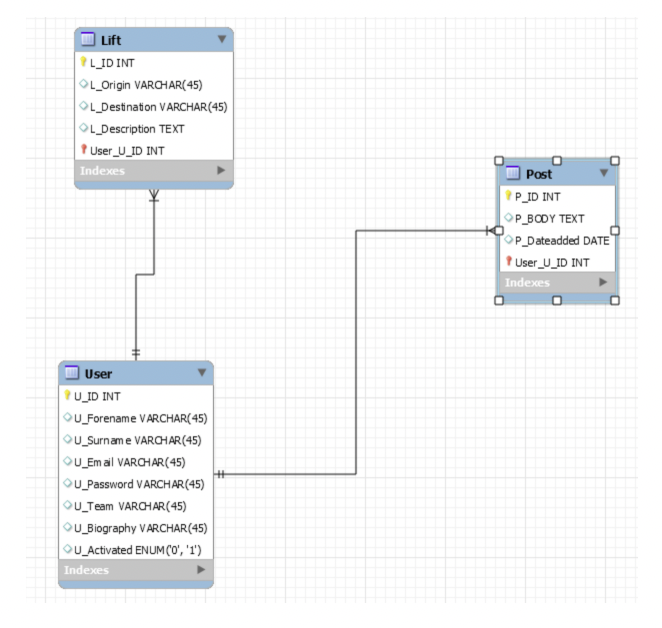
- 스키마는 데이터 베이스의 구조를 만드는 디자인
강의 계획 및 클라우드 시스템에 대한 간단한 소개:


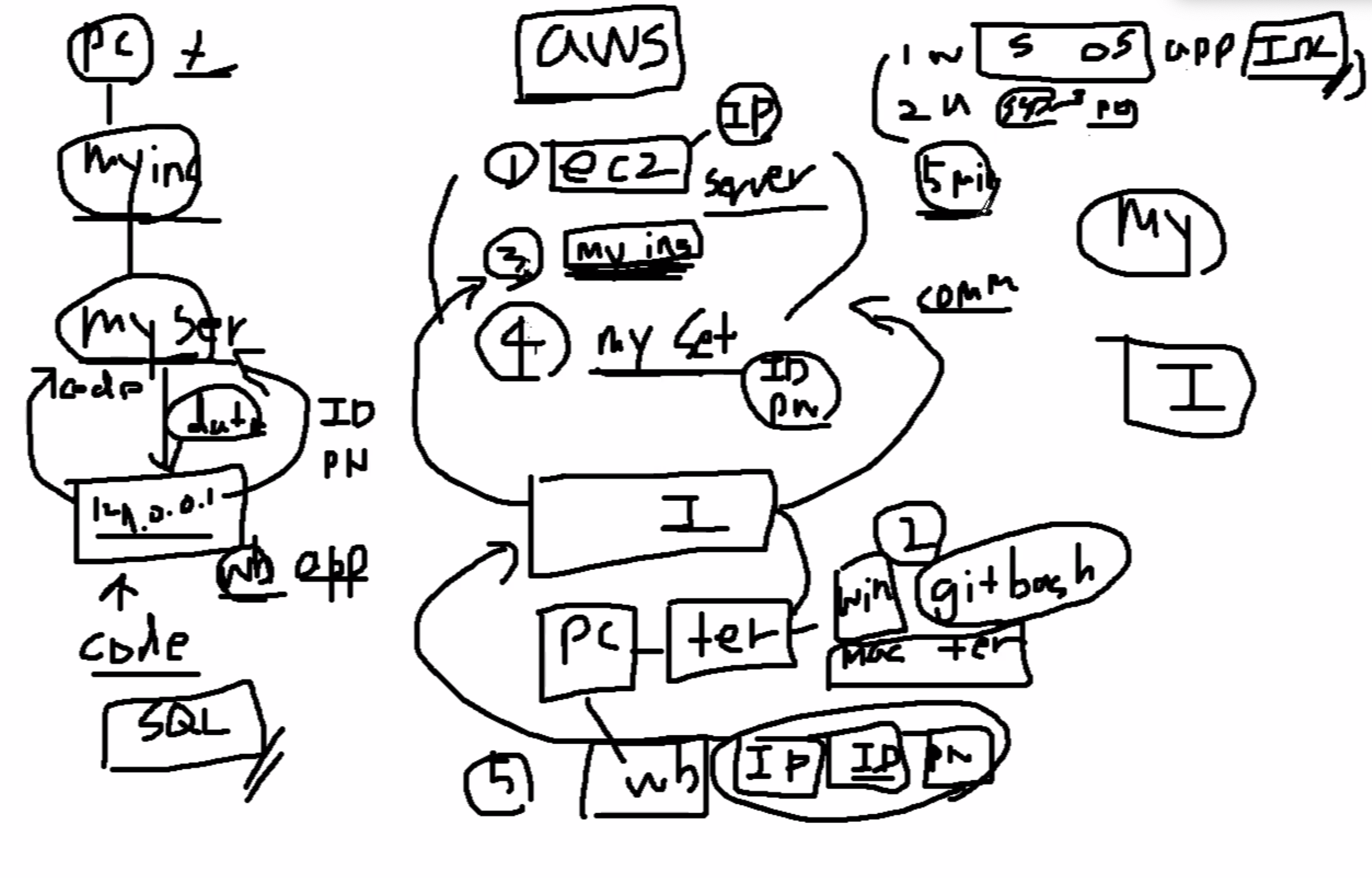
AWS를 활용한 환경설정:
- 리전: 서울 리전 사용
- AMI: Ubuntu Server 20.04 LTS
- 인스턴스 타입: t2.micro
- 스토리지: 8GiB
- 로그인 타입: 키페어 활용
- 보안그룹: SSH(22), MySQL/Aurora(3306)
- 퍼블릭 IP: EIP 활용
# 터미널에서 SSH 접속
$ ssh ubuntu@<EIP> -i <pem 파일>
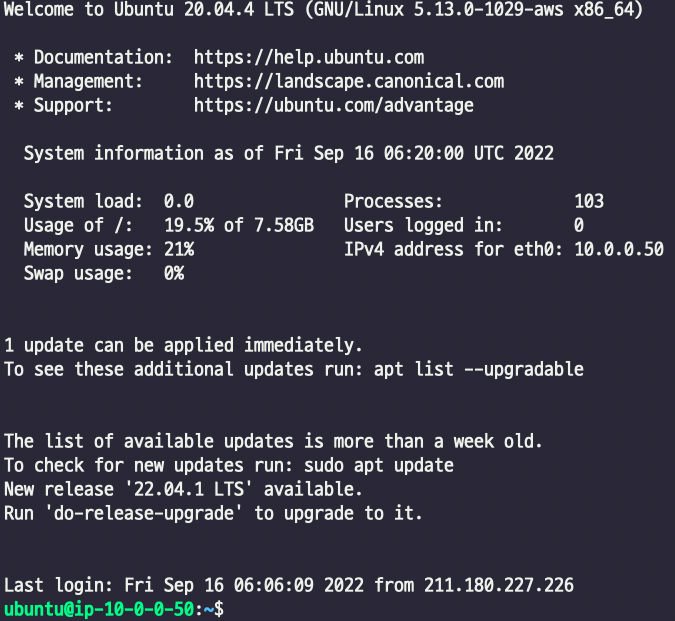
# apt-get 업데이트
sudo apt-get update -y
sudo apt-get upgrade -y
# MySQL 설치
sudo apt-get install -y mysql-server mysql-client
# MySQL 패스워드 설정
sudo mysql
mysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'test';
Query OK, 0 rows affected (0.01 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
mysql> exit
Bye
# 설정한 패스워드를 입력하여 접속
# 패스워드를 입력해도 입력하는 패스워드는 보이지 않습니다.
$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 9
Server version: 8.0.30-0ubuntu0.20.04.2 (Ubuntu)
mysql> exit
Bye
# 외부접속 설정
$ sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
# bind-address를 127.0.0.1을 0.0.0.0 으로 변경
------------------------------------------------------------------------------------------------
bind-address = 0.0.0.0
------------------------------------------------------------------------------------------------

# 계정생성 및 권한설정
mysql -u root -p
Enter password:
mysql> CREATE USER 'root'@'%' IDENTIFIED BY 'test';
Query OK, 0 rows affected (0.02 sec)
mysql> GRANT ALL PRIVILEGES ON *.* to 'root'@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> exit
Bye
# 서비스 재시작
sudo systemctl restart mysql
# 서비스 상태 확인
sudo systemctl status mysql
● mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2022-09-16 07:31:27 UTC; 56s ago
Process: 22518 ExecStartPre=/usr/share/mysql/mysql-systemd-start pre (code=exited, sta>
Main PID: 22526 (mysqld)
Status: "Server is operational"
Tasks: 39 (limit: 1145)
Memory: 361.4M
CGroup: /system.slice/mysql.service
└─22526 /usr/sbin/mysqld
Sep 16 07:31:26 ip-10-0-0-50 systemd[1]: mysql.service: Succeeded.
Sep 16 07:31:26 ip-10-0-0-50 systemd[1]: Stopped MySQL Community Server.
Sep 16 07:31:26 ip-10-0-0-50 systemd[1]: Starting MySQL Community Server...
Sep 16 07:31:27 ip-10-0-0-50 systemd[1]: Started MySQL Community Server.
DBMS Tool을 활용한 DB 접속:
저는 DBeavor를 활용하여 테스트를 진행하였습니다.
하단에 MySQL Workbench 사용 가이드도 작성하였습니다!
DBeavor Main URL: https://dbeaver.io/
DBeaver Community | Free Universal Database Tool
DBeaver Universal Database Tool Free multi-platform database tool for developers, database administrators, analysts and all people who need to work with databases. Supports all popular databases: MySQL, PostgreSQL, SQLite, Oracle, DB2, SQL Server, Sybase,
dbeaver.io



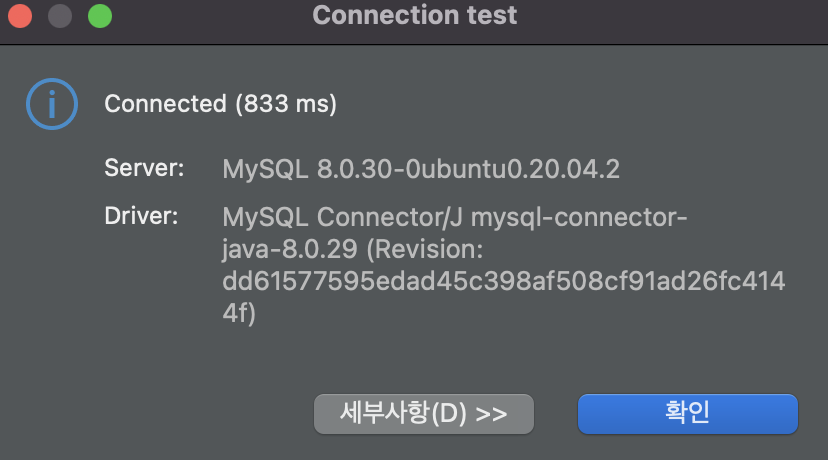

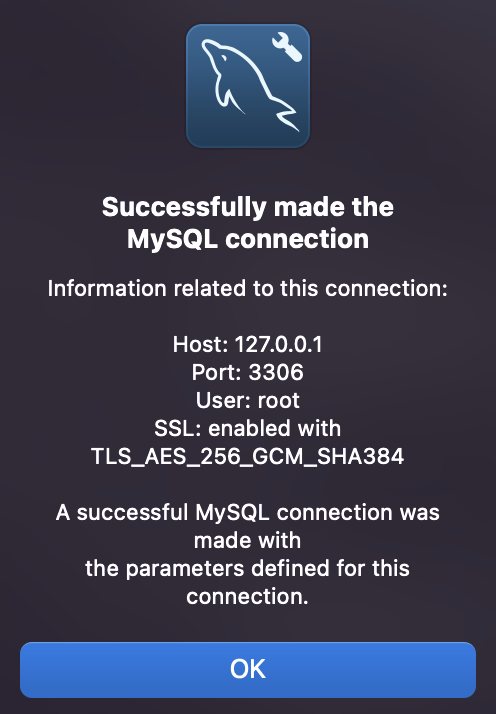
추가사항: MySQL Workbench 사용
# 설치
brew install mysqlworkbench

데이터베이스 모델링:
- 모델링은 데이터베이스에서의 테이블 구조를 미리 계획해서 작성하는 작업입니다.
- RDBMS는 테이블간에 유기적으로 연결되어 있기 때문에 모델링을 잘하는것이 중요합니다.
- 기본적으로 개념적 모델링, 논리적 모델링, 물리적 모델링 절차로 설계됩니다.
개념적 모델링:

업무 분석을 진행해서 핵심 데이터의 집합을 정의하는 과정!
논리적 모델링:

개념적 모델링을 상세화 하는 과정!
cf) 관계선
선 세개: 고객 한명이 구매를 여러개함 (선 세개)
물리적 모델링:

논리적 모델링을 DBMS에 추가하기 위해 구체화 되는 과정!
모델링 실습:
cf) Hacker Typer:
구글에서 hackertyper를 검색해서 들어가면 초고수의 기분을 느낄 수도 있다! 🤣
Hacker Typer main URL: https://hackertyper.net/
Hacker Typer
About Created in 2011, Hacker Typer arose from a simple desire to look like the stereotypical hacker in movies and pop culture. Since that time, it has brought smiles to millions of people across the globe. Plus, many of you have temporarily transformed in
hackertyper.net
/** SQL 모델링 실습 **/
/** File 탭 > New Model 클릭 **/
/** mydb 더블 클릭 > DB 이름 변경 > test 로 변경 완료! **/
/** Add Diagram 더블 클릭! **/
/** Place a New Table 선택 > 모눈종이 클릭 > 반복! **/
/** 생성한 Table 더블클릭 > Name 변경 **/
/** **/
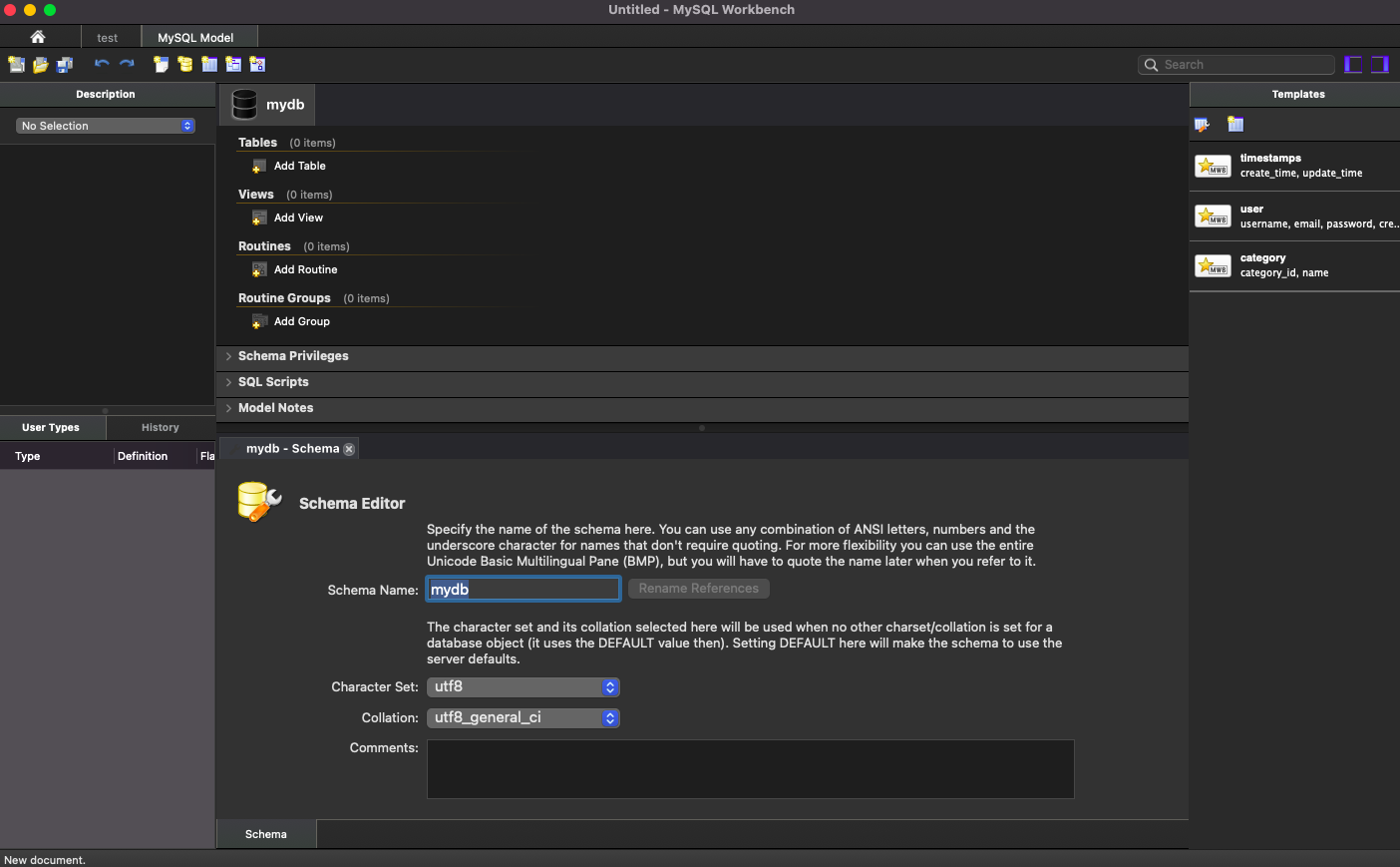

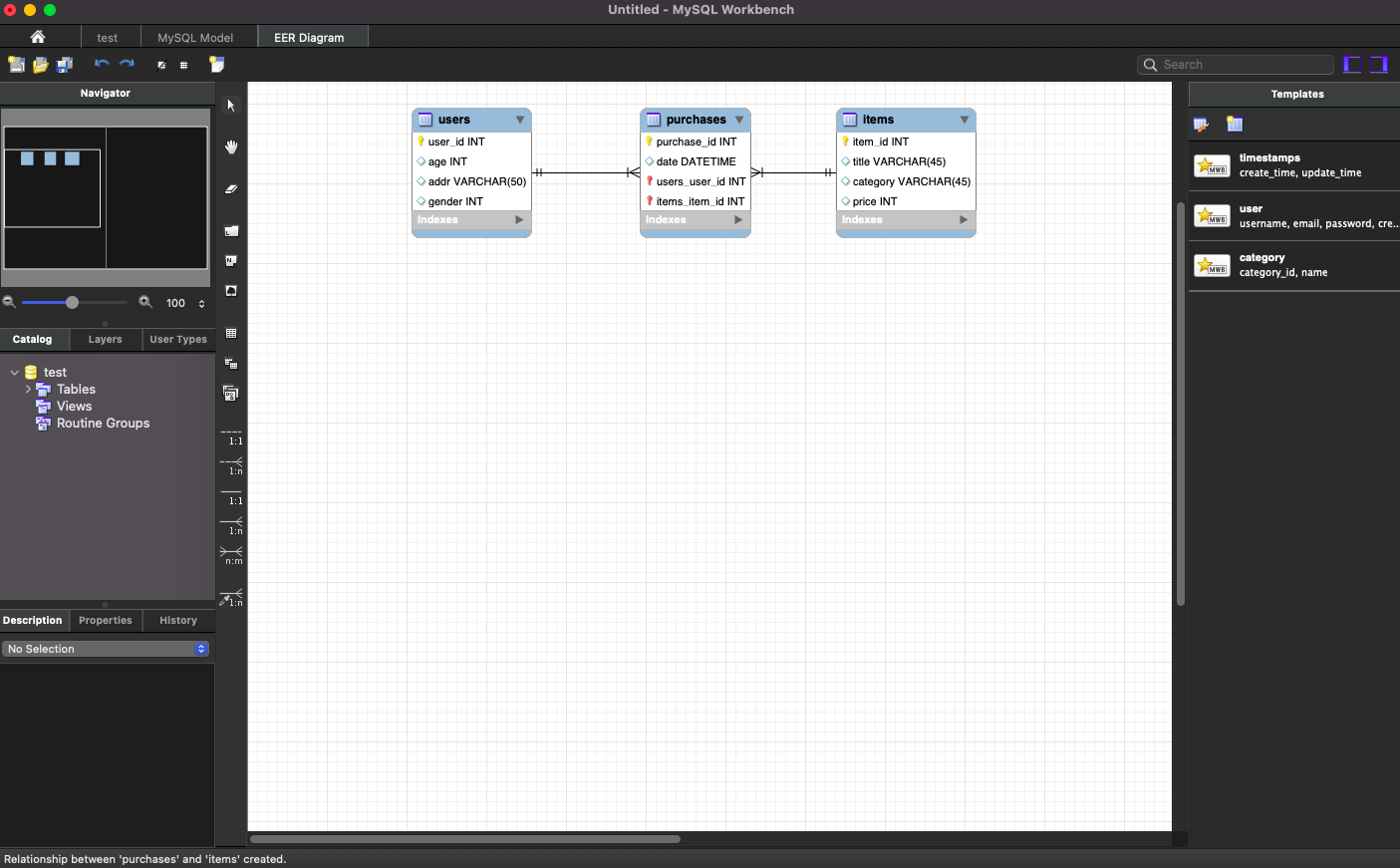
Database 탭 > Forward Engineer 선택!
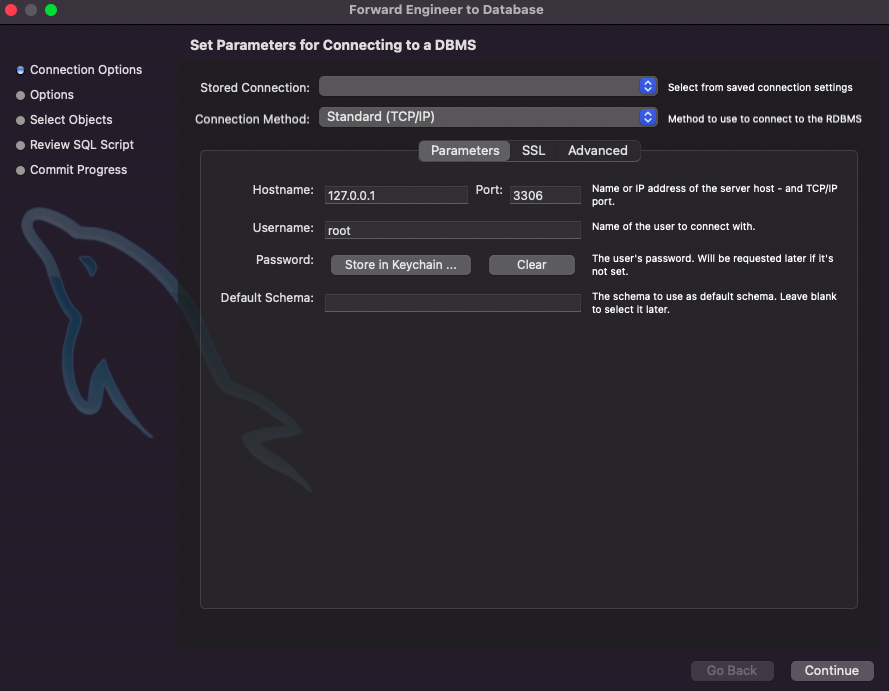
Stored Connection 항목에서 생성한 DB 선택! > Continue 버튼 클릭 > Continute 버튼 쭉쭉 클릭!!

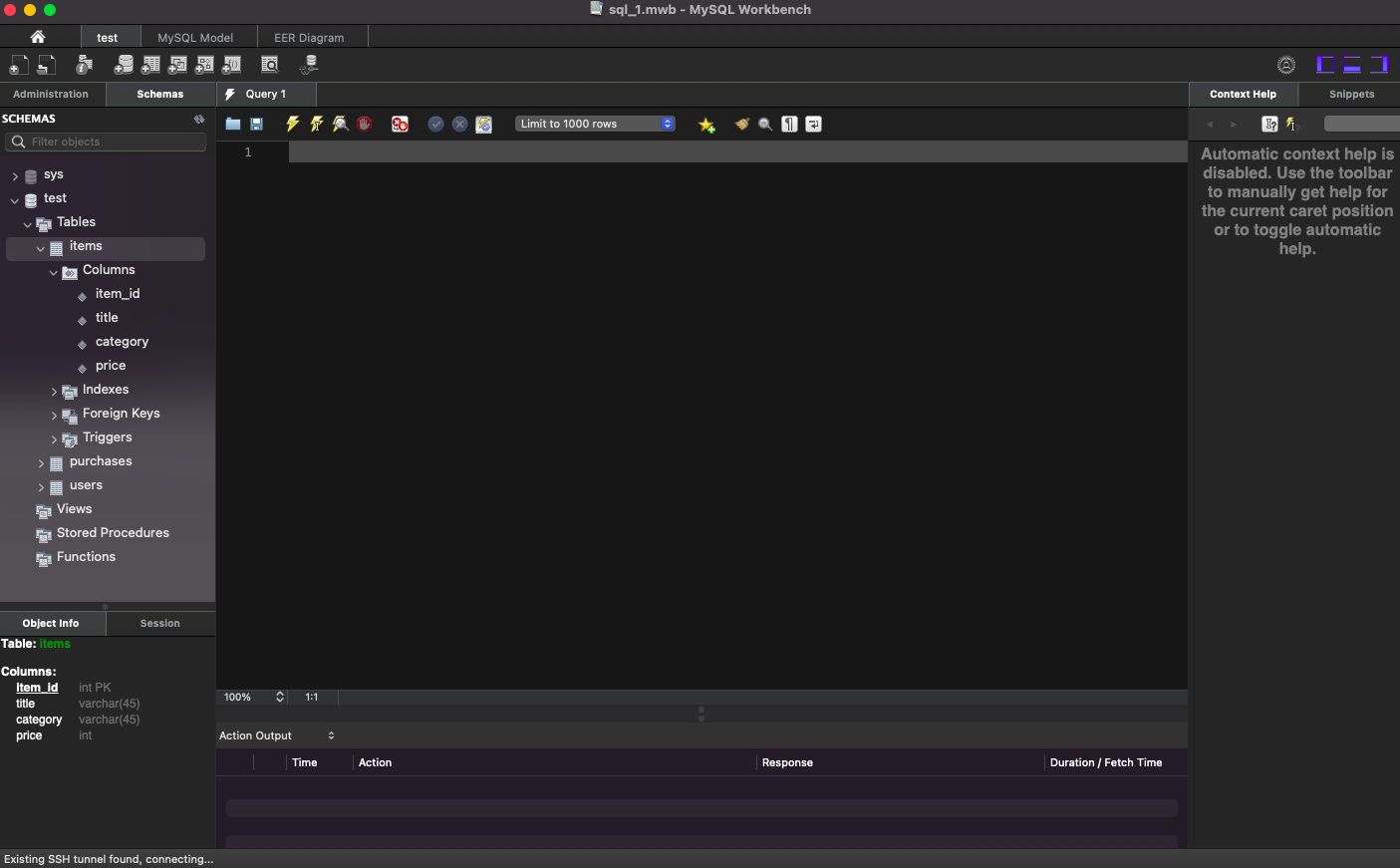
Schemas 탭 > 우클릭 > Refresh All

샘플 데이터 업로드:
- world.sql
- sakila-data.sql
- sakila-schemas.sql

File 탭 > Open SQL Script > world.sql 오픈! > 번개모양 아이콘 클릭!
world.sql의 경우 스키마와 데이터가 통합!

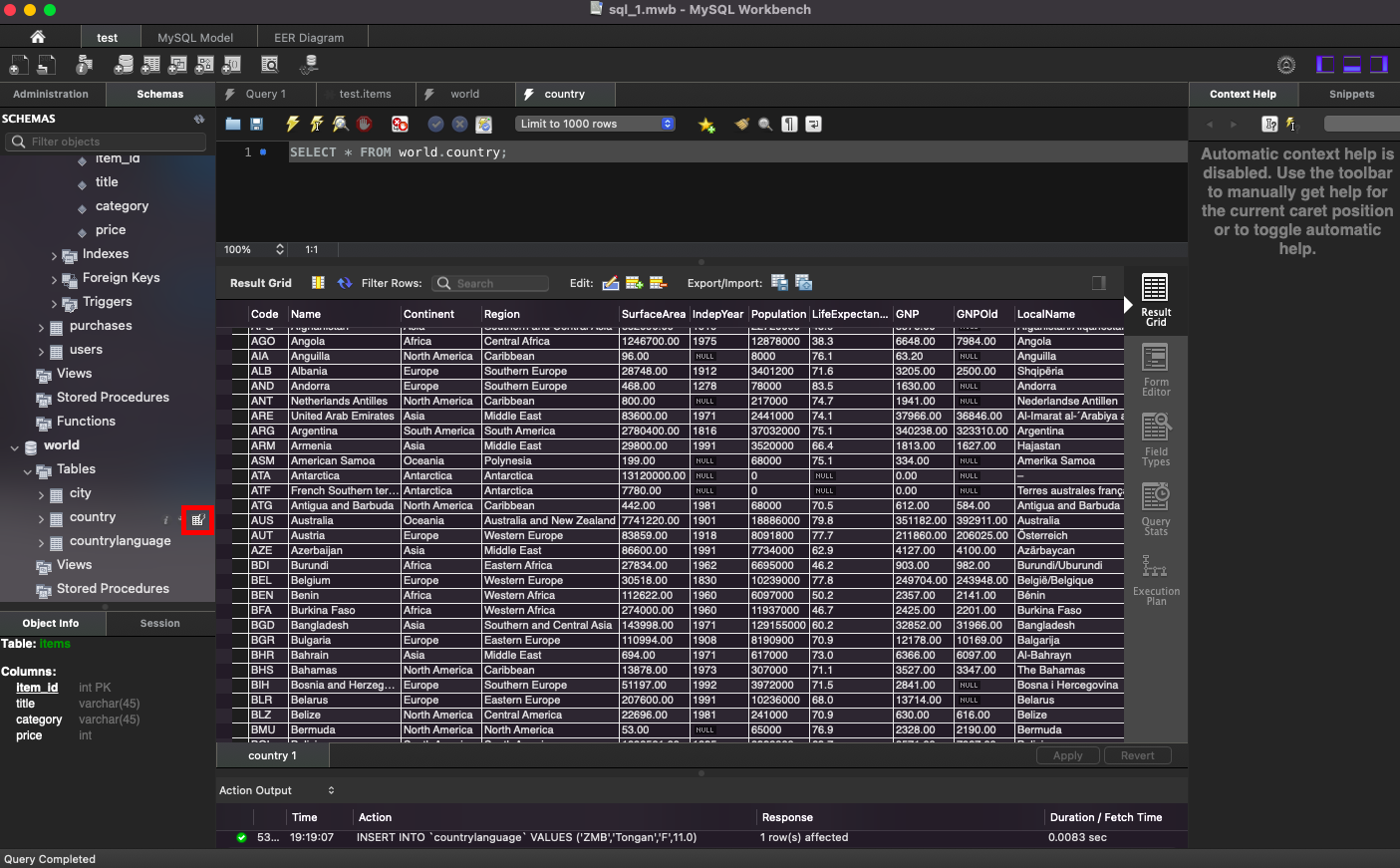

Reverse Engineer:
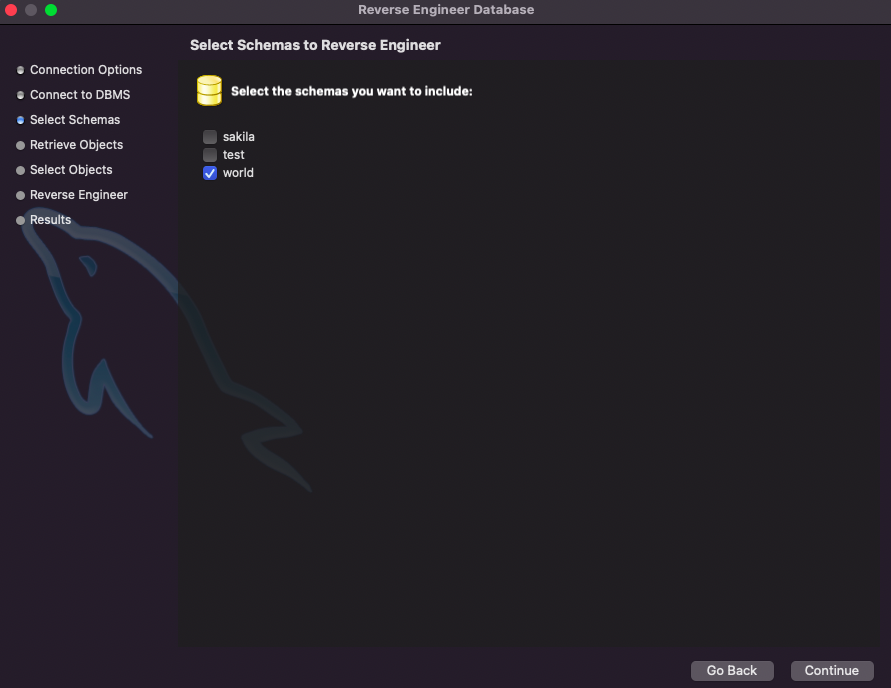
Database 탭 > Reverse Engineer > world 만 선택 > Continue 쭉쭉! > Execute > Continue > Close

점선 예시: 싱가폴 > country는 있지만 city는 없을 수 있다 (도시국가)
cf) Scrapy
파이썬을 활용한 웹상 데이터 수집하는 프레임워크!
자동으로 멀티 스레드 수집, robot.txt 규칙 체크, 오픈소스!!
Scrapy main URL: https://scrapy.org/
Scrapy | A Fast and Powerful Scraping and Web Crawling Framework
Portable, Python written in Python and runs on Linux, Windows, Mac and BSD
scrapy.org
SQL:
SQL 문의 종류: DML, DDL, DCL
DML
- Data Manipulation Language
- 데이터 조작어(데이터 자체를 다룰 때 사용!, ex) 엑셀의 데이터 입력과 비슷)
- 데이터 검색, 삽입, 수정, 삭제등에 사용
- SELECT, INSERT, UPDATE, DELETE
- 트랜젝션이 발생하는 SQL문
- CRUD (Create, Read, Update, Delete)
- C(insert into)
- R(select from)
- U(update set)
- D(delete from)
DDL
- Data Definition Language
- 데이터 정의어
- 데이터 베이스, 테이블, 뷰, 인덱스등의 데이터 베이스 개체를 생성, 삭제, 변경에 사용
- CREATE, DROP, ALTER, TRUNCATE
- 실행 즉시 DB에 적용
- CRUD (Create, Read, Update, Delete)
- C(create)
- R(show, desc)
- U(alter)
- D(drop)
DCL
- Data Control Language
- 데이터 제어어
- 사용자의 권한을 부여하거나 빼앗을때 사용
- GRUNT, REVORKE, DENY
- 과정에서 다루지는 않음!
cf) 트랜잭션:
DML - 묶어서 처리!
서로 겹쳐서 일어나는 충돌 방지 가능!
DML : READ : select from
where, order by, limit
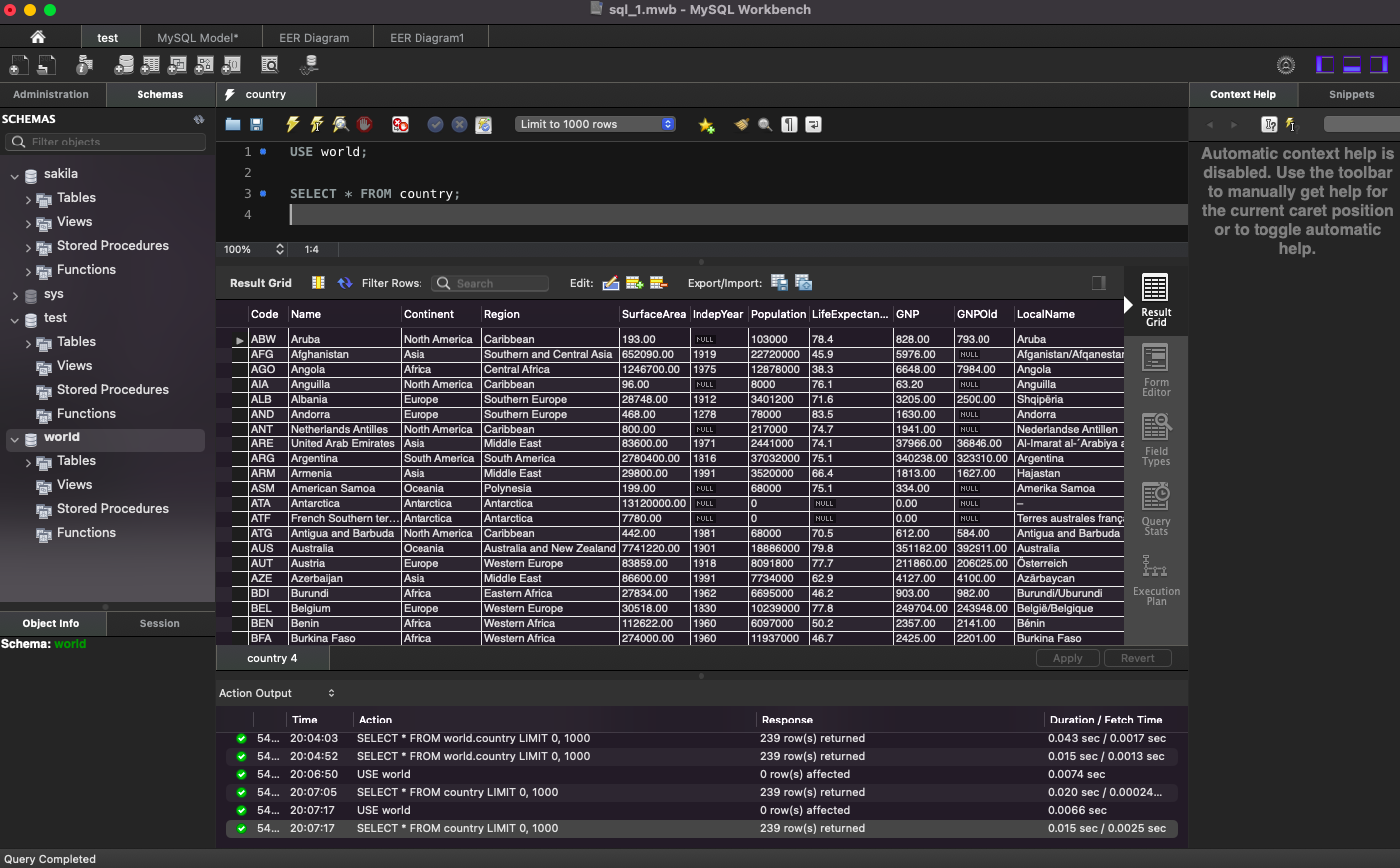
world 데이터베이스의 country 테이블에 있는 데이터 출력:
SELECT *
FROM world.country;

# 데이터베이스 선택 후, 테이블 데이터 조회
# 데이터베이스 선택
USE world;
SELECT * FROM country;
cf) PEP8: 파이썬 코딩 스타일 가이드
PEP8 Main URL: https://peps.python.org/pep-0008/
PEP 8 – Style Guide for Python Code | peps.python.org
PEP 8 – Style Guide for Python Code Author: Guido van Rossum , Barry Warsaw , Nick Coghlan Status: Active Type: Process Created: 05-Jul-2001 Post-History: 05-Jul-2001, 01-Aug-2013 Table of Contents This document gives coding conventions for the Python co
peps.python.org
# 컬럼에 따른 데이터 조회
SELECT code, name, population
FROM country;
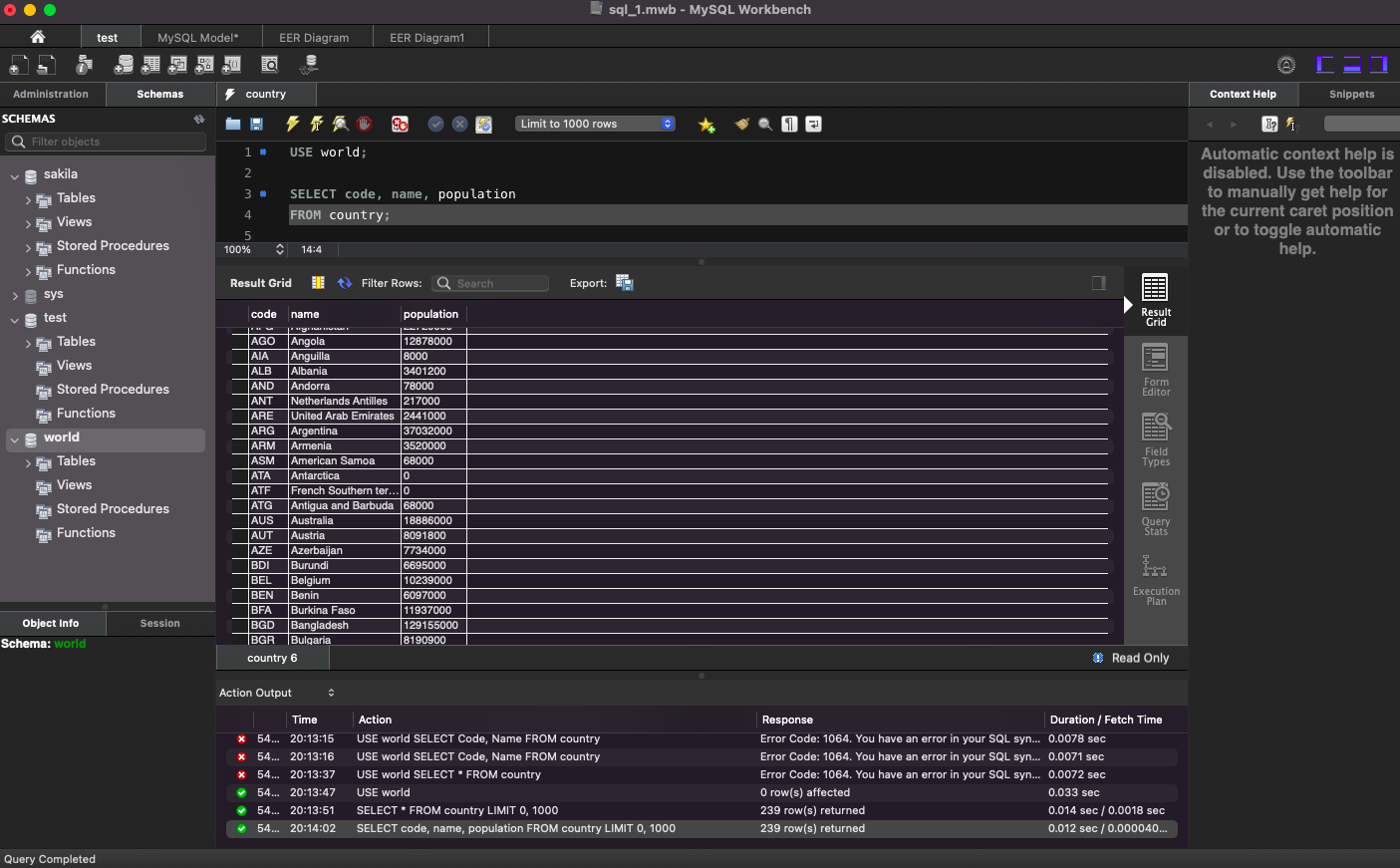
# as: alias
SELECT code, name as country_name, population
FROM country;

# DDL : READ : show
# 데이터베이스 목록 조회
SHOW databases;
# 테이블 리스트회조회
SELECT database();
# 테이블 리스트 조회
SHOW tables;

연산자:
# 연산자 : 산술, 비교, 논리
# 산술연산자 : +, -, *, /, %
# 데이터 +(산술) 데이터 = 데이터
# country 테이블에서 국가코드, 국가이름, 국가면적, 국가인구수, 인구밀도 출력
# 인구밀도= (국가인구수 / 국가면적)
SELECT code, name, surfacearea, population, population/surfacearea
FROM country;

# world 데이터베이스에서 국가코드, 국가이름, 1인당 GNP를 출력
# 1인당 GNP = (gnp/population) as gpp
SELECT code, name, gnp/population * 1000 as gpp
FROM country;

# 비교연산자 : =, !=, >, <, >=, <=
# 데이터 +(비교) 데이터 = 논리값(bool:True, False)
# True(1), False(0)
# 국가이름, 대륙이름, 아시아대륙이면 1 출력하는 쿼리 작성
# (asia = 1)
SELECT name, continent, continent = 'asia' as is_asia
FROM country;

# 논리연산자 : and(T and T = T), or(F and F = F)
# 논리값 +(논리) 논리값 = 논리값
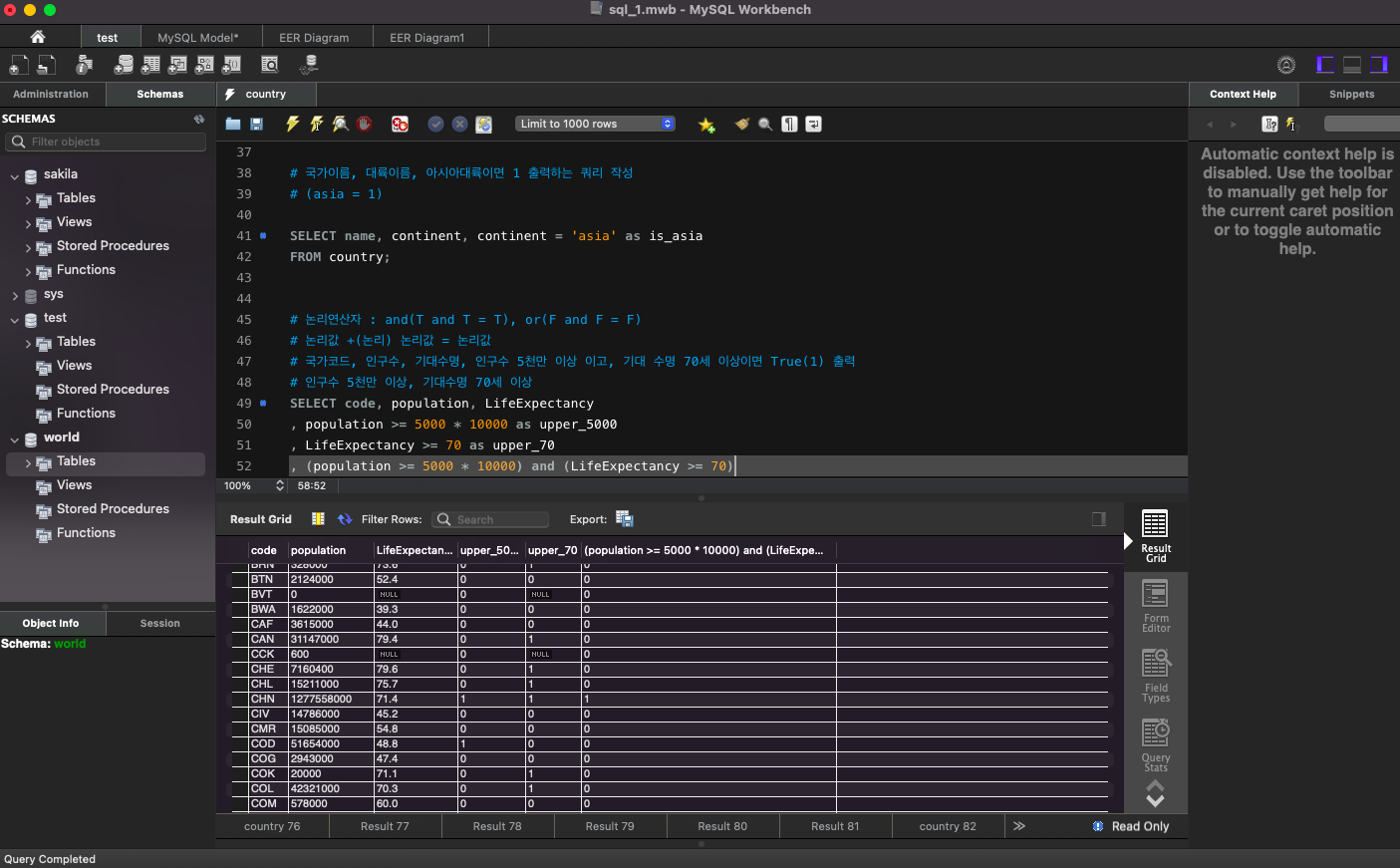
# 국가코드, 인구수, 기대수명, 인구수 5천만 이상 이고, 기대 수명 70세 이상이면 True(1) 출력
# 인구수 5천만 이상, 기대수명 70세 이상
SELECT code, population, LifeExpectancy
, population >= 5000 * 10000 as upper_5000
, LifeExpectancy >= 70 as upper_70
, (population >= 5000 * 10000) and (LifeExpectancy >= 70)
FROM country;
cf) 데이터의 크기에 따른 도구 사용
엑셀(17만개) < 파이썬(RAM용량) < 데이터베이스(SSD용량)
데이터에 맞는 도구를 사용해보자!

긴 글 읽어주셔서 감사합니다 :)
'AI > [부트캠프] 데이터 사이언티스트 과정' 카테고리의 다른 글
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 20. (0) | 2022.09.20 |
|---|---|
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 19. (0) | 2022.09.19 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 14. (0) | 2022.09.08 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 13. (0) | 2022.09.07 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 12. (0) | 2022.09.06 |