
안녕하세요 늑대양입니다 :)
오늘은 [AI 데이터 사이언티스트 취업 완성 과정]의 27일차 일과를 정리하여 안내해드리도록 하겠습니다.

Day 27 시간표:
- 온라인 학습: 파이썬 라이브러리 기초
- 실시간 강의: 데이터 분석을 위한 파이썬 라이브러리 기초
Day 27. 온라인 학습 범위:
- 6강
- 예상 학습 시간: 2:37:56
| 대주제(Part) | 중주제(Chapter) | 소주제(Clip) |
| Part.3 파이썬 기초와 데이터분석 | Chapter.02 데이터 분석 라이브러리 | CH02_01. Numpy를 사용하는 이유 |
| Part.3 파이썬 기초와 데이터분석 | Chapter.02 데이터 분석 라이브러리 | CH02_02. Numpy array |
| Part.3 파이썬 기초와 데이터분석 | Chapter.02 데이터 분석 라이브러리 | CH02_03. Numpy method |
| Part.3 파이썬 기초와 데이터분석 | Chapter.02 데이터 분석 라이브러리 | CH02_04. Pandas를 사용하는 이유 |
| Part.3 파이썬 기초와 데이터분석 | Chapter.02 데이터 분석 라이브러리 | CH02_05. Pandas DataFrame |
| Part.3 파이썬 기초와 데이터분석 | Chapter.02 데이터 분석 라이브러리 | CH02_06. Pandas method |
Part.3 파이썬 기초와 데이터분석
Chapter.02 데이터 분석 라이브러리
CH02_01. Numpy를 사용하는 이유
Numpy : Numerical computing with Python. 수치연산 및 벡터 연산에 최적화된 라이브러리
Numpy main URL: https://numpy.org/
NumPy
Powerful N-dimensional arrays Fast and versatile, the NumPy vectorization, indexing, and broadcasting concepts are the de-facto standards of array computing today. Numerical computing tools NumPy offers comprehensive mathematical functions, random number g
numpy.org
- 2005년에 만들어졌으며, 100% 오픈소스입니다.
- 최적화된 C code로 구현되어 있어 엄청나게 좋은 성능을 보입니다.
- 파이썬과 다르게 수치 연산의 안정성이 보장되어 있습니다. (numerical stable)
- N차원 실수값 연산에 최적화되어 있습니다. == N개의 실수로 이루어진 벡터 연산에 최적화되어 있습니다.
# numpy example
import numpy as np # 국룰!
arr = np.array([1, 2, 3]
print(np.linalg.norm(arr)) # print L2 norm of vector (1, 2, 3)
Numpy를 사용해야 하는 이유
- 데이터는 벡터로 표현됩니다. 데이터 분석이란 벡터 연산입니다. 그러므로 벡터 연산을 잘해야 데이터 분석을 잘할 수 있습니다.
- (native) 파이썬은 수치 연산에 매우 약합니다. 실수값 연산에 오류가 생기면 (numerical error) 원하는 결과를 얻지 못할 수 있습니다. 많은 실수 연산이 요구되는 머신러닝에서 성능 저하로 이어질 수 있습니다.
- numpy는 벡터 연산을 빠르게 처리하는 것에 최적화되어 있습니다. 파이썬 리스트로 구현했을 때보다 훨씬 더 높은 속도를 보여줍니다.
CH02_02. Numpy array
Numpy array: numpy에서 사용되는 기본적인 자료구조

- numpy array는 C언어의 array 구조와 동일한 개념입니다.
- numpy array는 파이썬 리스트와 비슷한 구조입니다. 하지만, 세부적인 특징이 많이 다릅니다.
< 리스트와 다른 점>
- 선언한 이후에 크기 변경이 불가능합니다.
- 모든 원소의 데이터 타입이 동일해야 합니다. (homogeneous array)
< 리스트와 같은 점>
- indexing으로 원소를 접근할 수 있습니다.
- 생성 후 assignment operator를 이용해서 원소의 update가 가능합니다.

- numpy가 제공하는 데이터 타입은 파이썬과 다릅니다.
- 수치와 관련된 데이터 타입이 대부분입니다.
- 원소의 크기(memory size)를 조절할 수 있으며, 크기에 따라 표현할 수 있는 수치 범위가 정해집니다.
e.g. np.int8 → 수치 표현에 8 bits를 사용한다 → 00000000 ~ 11111111 → 2^8 (256개) → -128 ~ 127
e.g. np.float32 → 실수 표현에 32 bits를 사용한다 → exponent, mantissa, sign → 2.813 x 10^23 → single precision
CH02_03. Numpy method
CH02_04. Pandas를 사용하는 이유
CH02_05. Pandas DataFrame
CH02_06. Pandas method
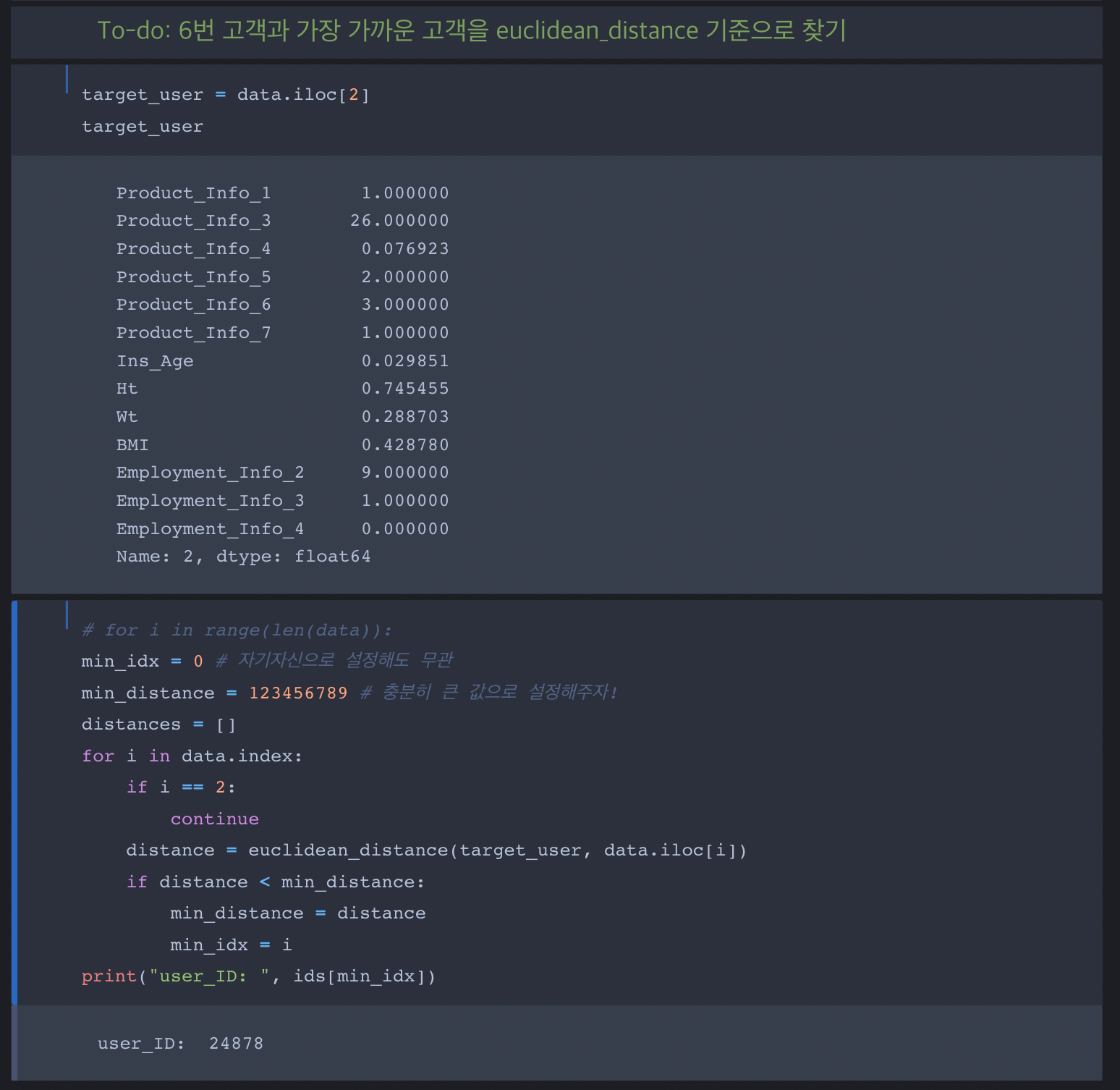
데이터분석을 위한 선형대수학 예제 - 1


데이터분석을 위한 선형대수학 예제 - 2
Data source URL: https://www.kaggle.com/competitions/prudential-life-insurance-assessment/data
Prudential Life Insurance Assessment | Kaggle
www.kaggle.com

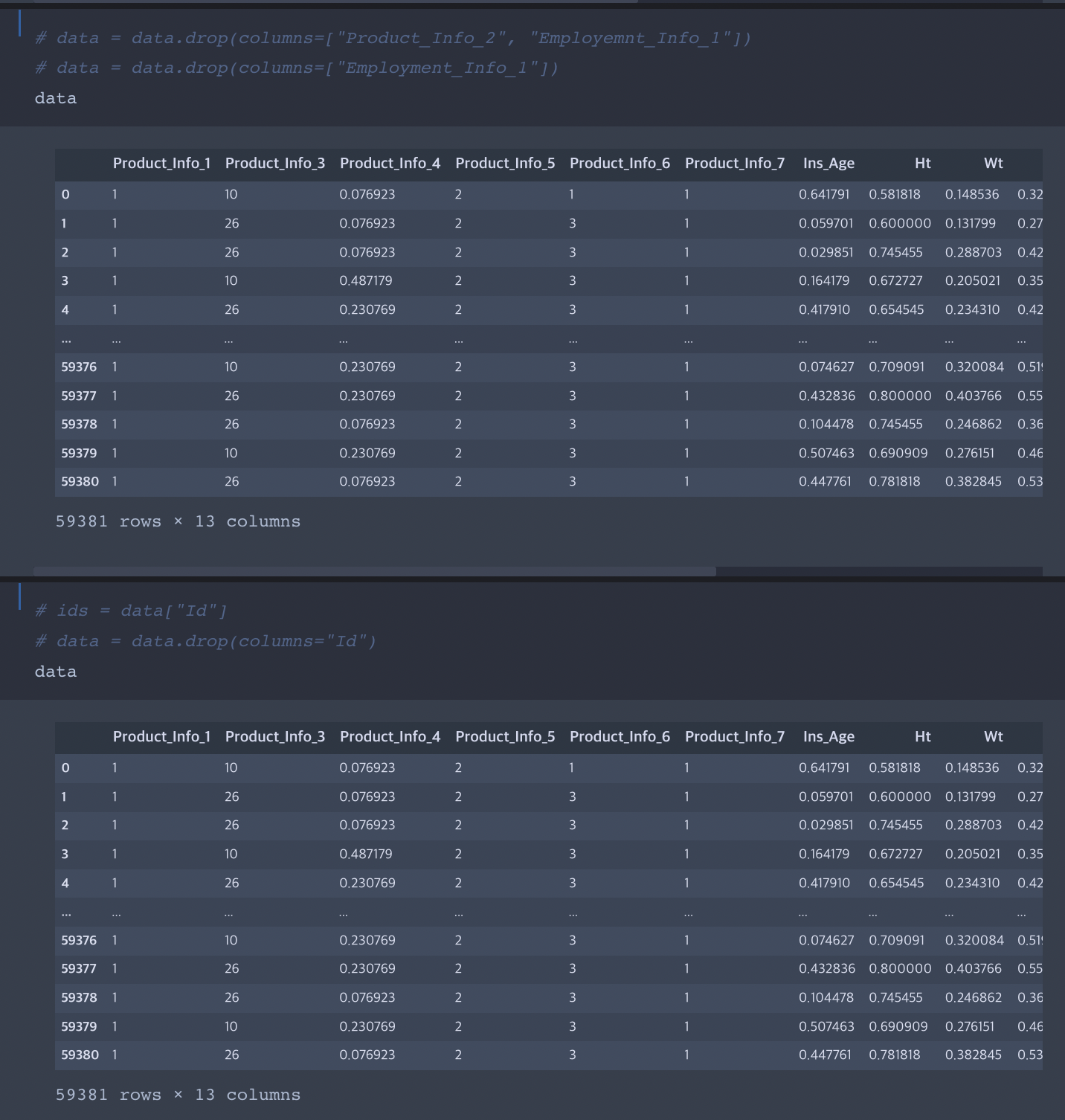
데이터 전처리를 위한 라이브러리
Numpy
Numpy main URL: https://numpy.org/
NumPy
Powerful N-dimensional arrays Fast and versatile, the NumPy vectorization, indexing, and broadcasting concepts are the de-facto standards of array computing today. Numerical computing tools NumPy offers comprehensive mathematical functions, random number g
numpy.org
- 파이썬은 기본적으로 수치연산, 벡터연산에 약함
- 이러한 약점을 보완하기 위한 근본!
- XGBoost, LightGBM 등등 여러가지 분야에서 사용
- numpy 함수의 디테일한 내용이 궁금할 경우, docs를 샅샅이 뒤져서 코드 및 기타 사용법을 확인하자!
numpy main github repo URL: https://github.com/numpy/numpy
GitHub - numpy/numpy: The fundamental package for scientific computing with Python.
The fundamental package for scientific computing with Python. - GitHub - numpy/numpy: The fundamental package for scientific computing with Python.
github.com
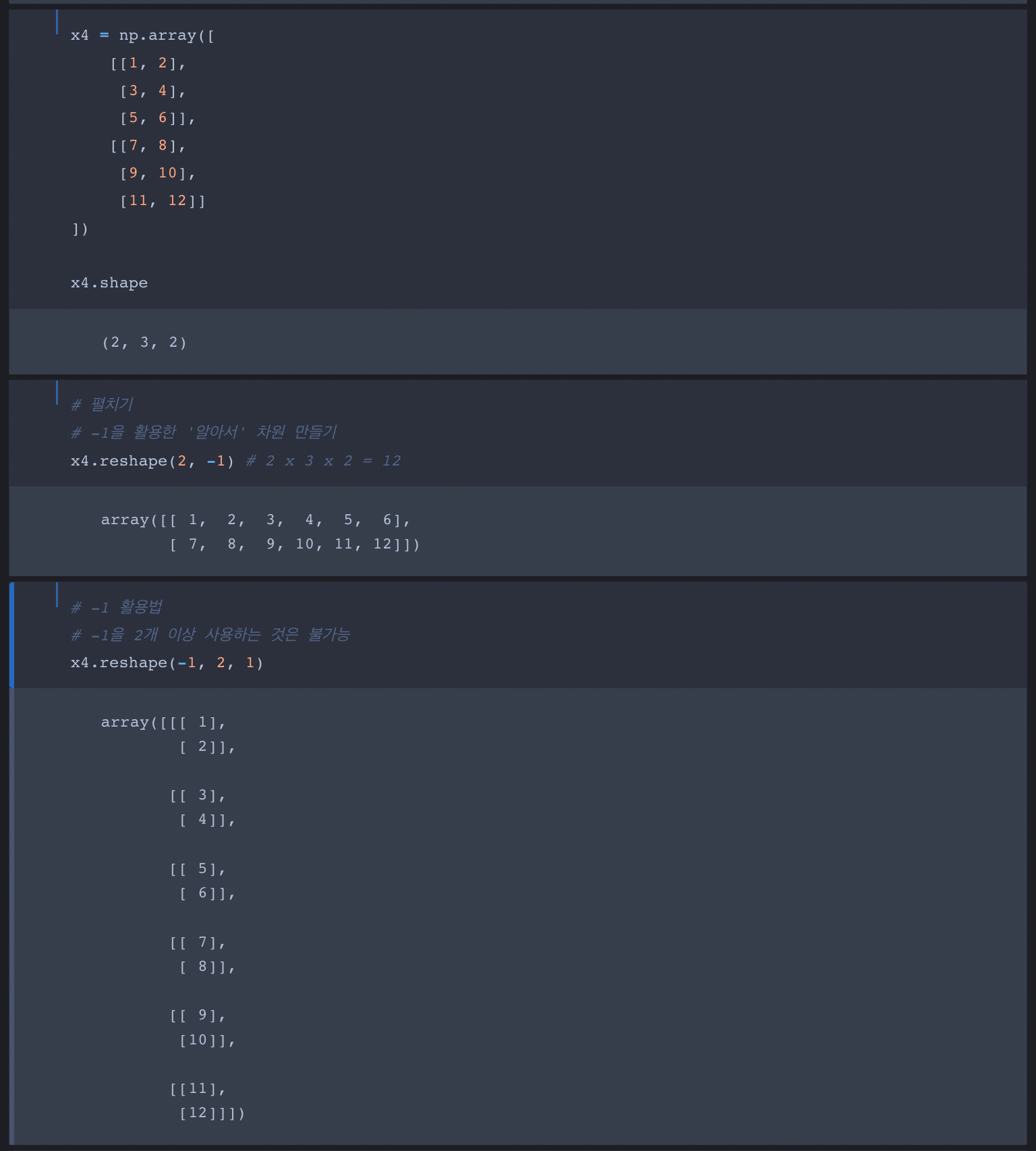
Numpy Array and Operation
- numpy의 기본적인 사용법에 대해서 배워봅니다.
- numpy에서 numpy.array를 만드는 여러가지 방법과 지원하는 연산자에 대해서 공부합니다.
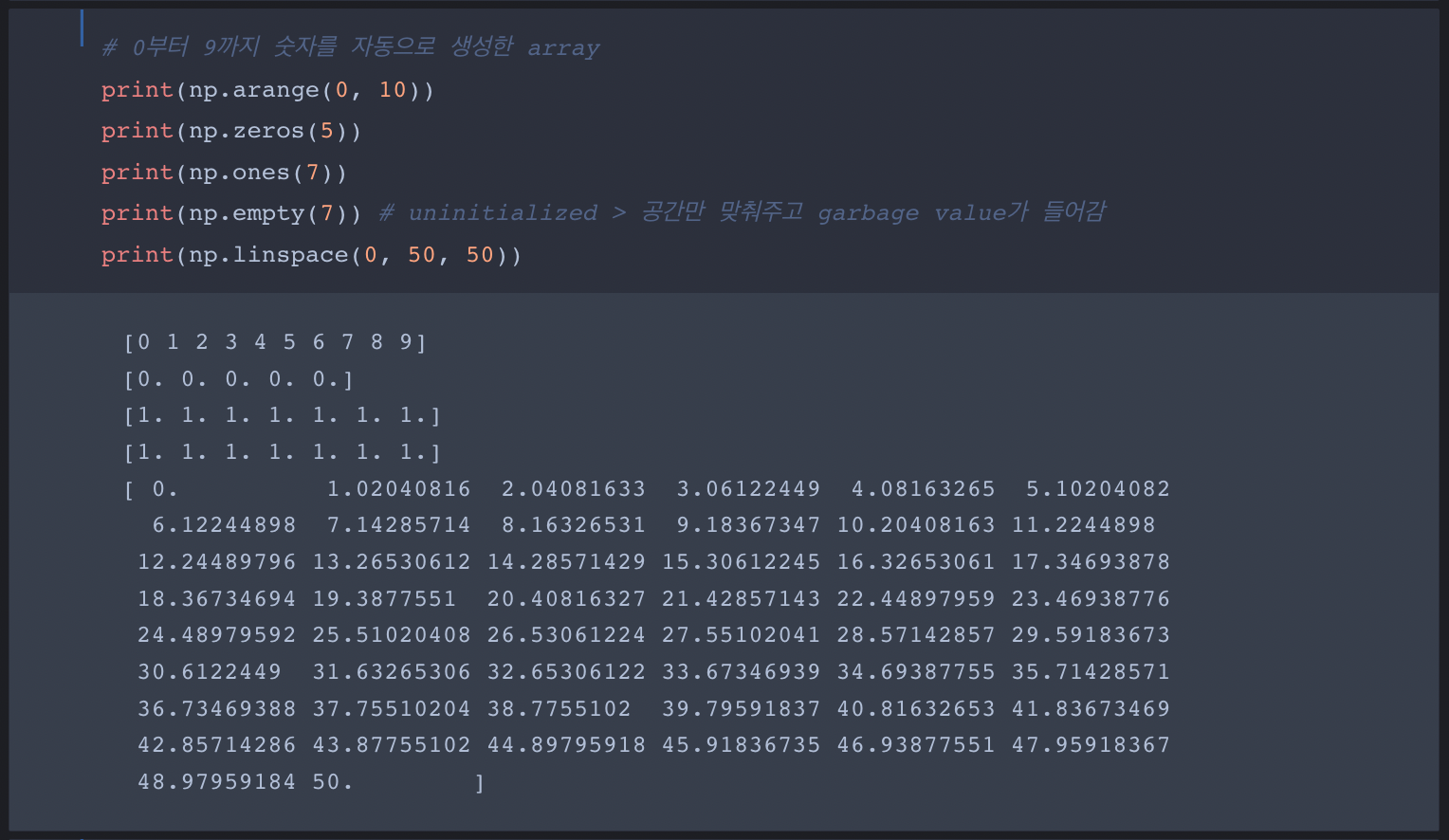
Numpy Array and Operation 실습:



긴 글 읽어주셔서 감사합니다 :)
'AI > [부트캠프] 데이터 사이언티스트 과정' 카테고리의 다른 글
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 29. (0) | 2022.10.04 |
|---|---|
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 28. (0) | 2022.09.30 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 26. (0) | 2022.09.28 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 25. (0) | 2022.09.27 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 24. (2) | 2022.09.26 |