
[CloudNet@] PKOS 스터디는 '24단계 실습으로 정복하는 쿠버네티스' 도서를 베이스로 진행됩니다!!
Related URL: https://www.yes24.com/Product/Goods/115187666
안녕하세요 늑대양입니다 😍

이번에 CloudNet@에서 진행하는 Production Kubernetes Online Study(PKOS)에 참여하여 관련 내용을 공유드리고자 합니다.
오늘은 PKOS 스터디 6주차 학습 내용을 안내해드리록하겠습니다.

CloudNet@ 팀 블로그 Main URL:
https://www.notion.so/gasidaseo/CloudNet-Blog-c9dfa44a27ff431dafdd2edacc8a1863
CloudNet@ Blog
CloudNet@ 팀에서 Cloud Infra & Network 기술에 대한 정보를 공유하는 블로그 입니다.
www.notion.so
Production Kubernetes Online Study - 6주차
6주차 학습 주제: 쿠버네티스 경보 & 로깅 (Alertmanager & Loki & PLG Stack)
Index.
- 이론
- 실습 환경 배포
- Alerting - 얼럿매니저
- PLG 스택
- (실습 완료 후) 자원 삭제
- 과제
- 과제 1. 책 367~372페이지 - 사용자 정의 prometheusrules 정책 설정 : 파일 시스템 사용률 80% 초과 시 시스템 경고 발생시키기 ⇒ 직접 실습 후 관련 스샷을 올려주세요
- 과제 2. 책 386~389페이지 - LogQL 사용법 익히기 ⇒ 직접 실습 후 관련 스샷을 올려주세요
- 과제 3. 아래 1,2 과제 중 하나를 해주시면 됩니다
- Awesome Prometheus alerts 를 참고해서 스터디에서 배우지 않은 Alert Rule 생성 및 적용 후 관련 스샷을 올려주세요
- 그라파나에서 그래프 이미지를 포함한 알람을 슬랙에 전달하게 설정 후 관련 스샷을 올려주세요
이론
실습 환경 배포
- kops 인스턴스 t3.small
- 노드 c5.2xlarge (vCPU 8, Mem 16GiB) x 3 (마스터, 워커 x2)
# CloudFormation 스택 배포 완료 후 kops EC2 IP 출력
aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text
# default NS로 스위칭
kubectl config set-context --current --namespace=default
# kOps 클러스터 편집 : 아래 내용 추가
# kubeproxy.metricsBindAddress 설정은 프로메테우스 kube-proxy 메트릭 수집을 위해서 설정 : 기본값 127.0.0.1 -> 수정 0.0.0.0 - 링크
kops edit cluster
-----
spec:
certManager:
enabled: true
awsLoadBalancerController:
enabled: true
externalDns:
provider: external-dns
metricsServer:
enabled: true
kubeProxy:
metricsBindAddress: 0.0.0.0
-----
# 업데이트 적용 : 모든 노드 롤링업데이트 필요 >> 마스터 EC2인스턴스 삭제 후 재생성 후 정상 확인 후, 워커노드 EC2인스턴스 생성 후 Join 후 삭제 과정 진행됨
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster --yes
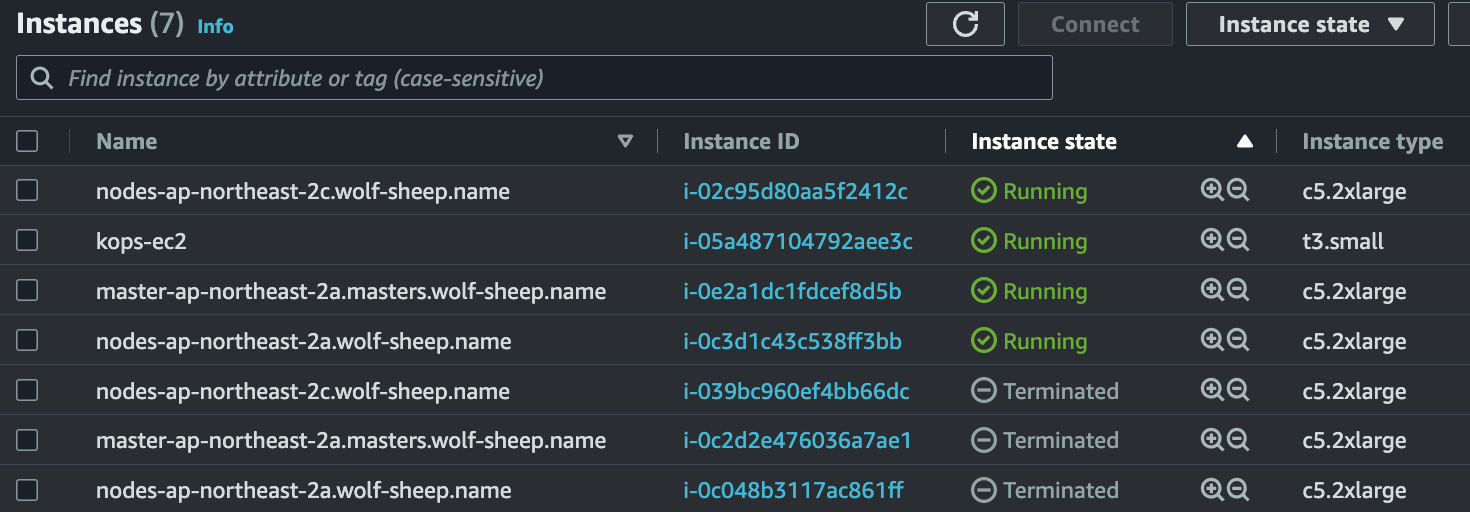
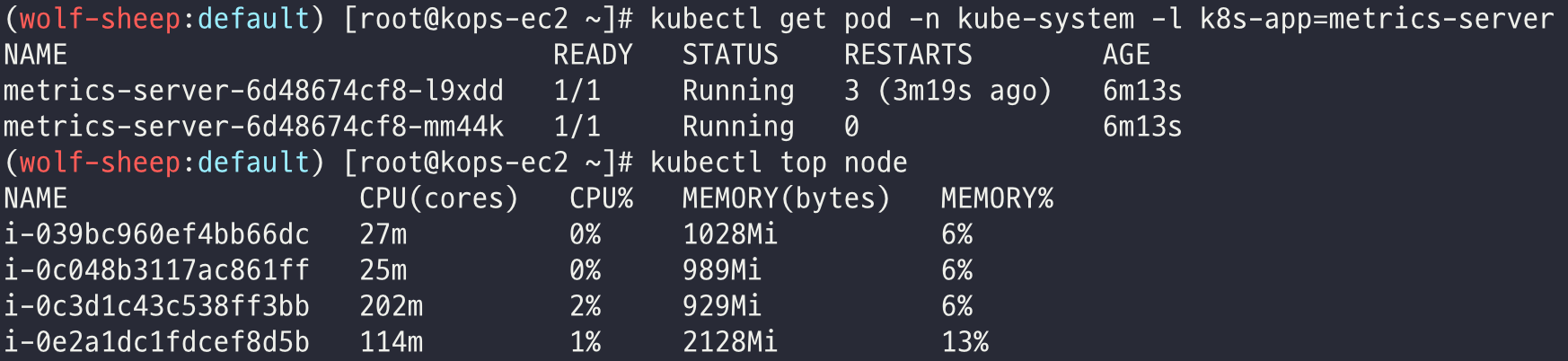
메트릭 서버 확인
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l k8s-app=metrics-server
kubectl top node
kubectl top pod -A
프로메테우스-스택 설치 및 웹 접속
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
# 설치
kubectl create ns monitoring
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.0.0 --set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' -f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
helm list -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
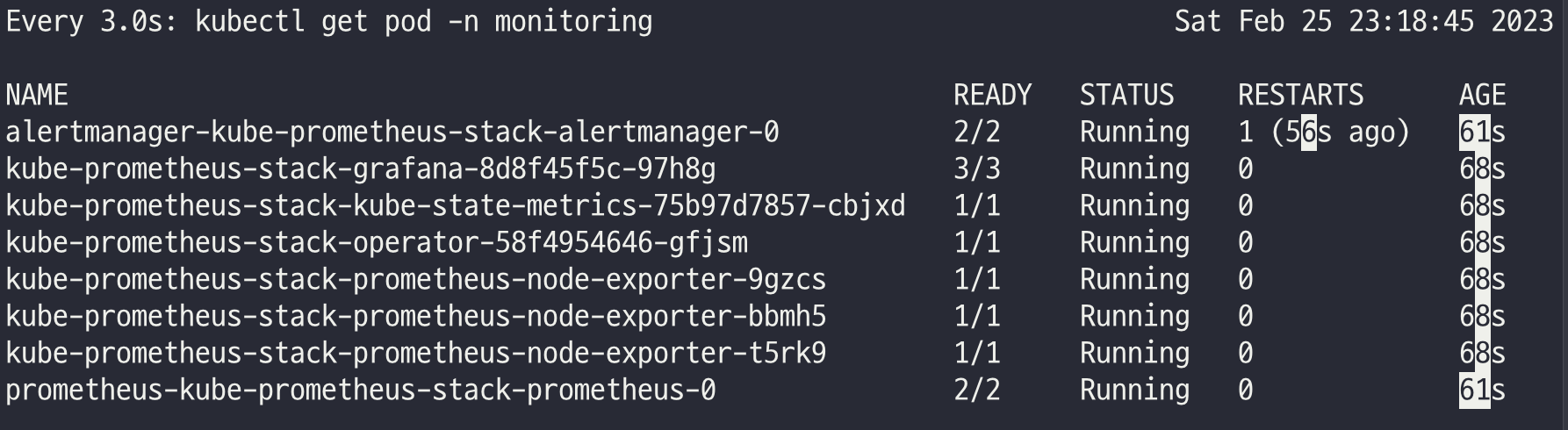
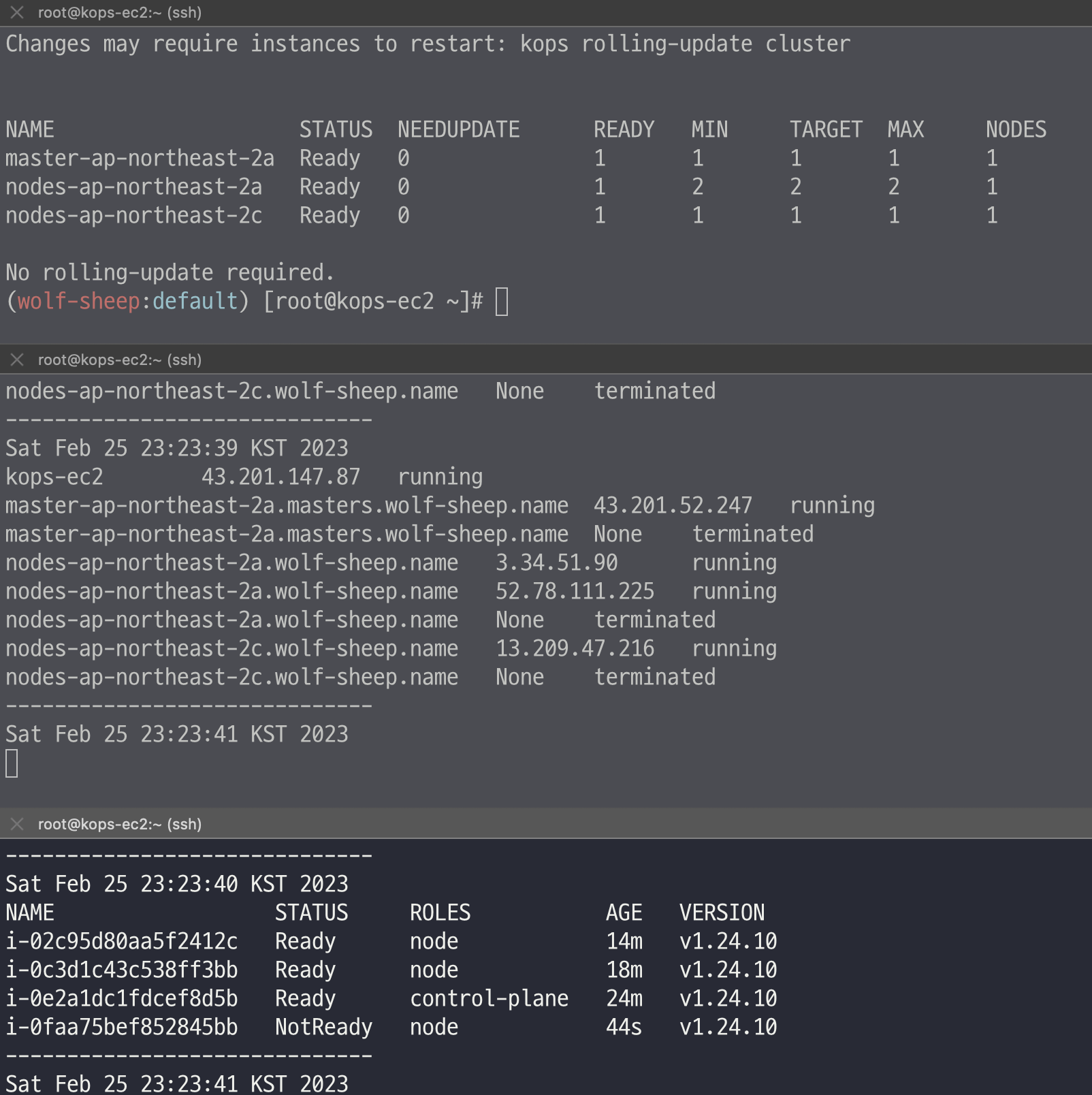
워커 노드 3번 추가
# EC2 인스턴스 모니터링
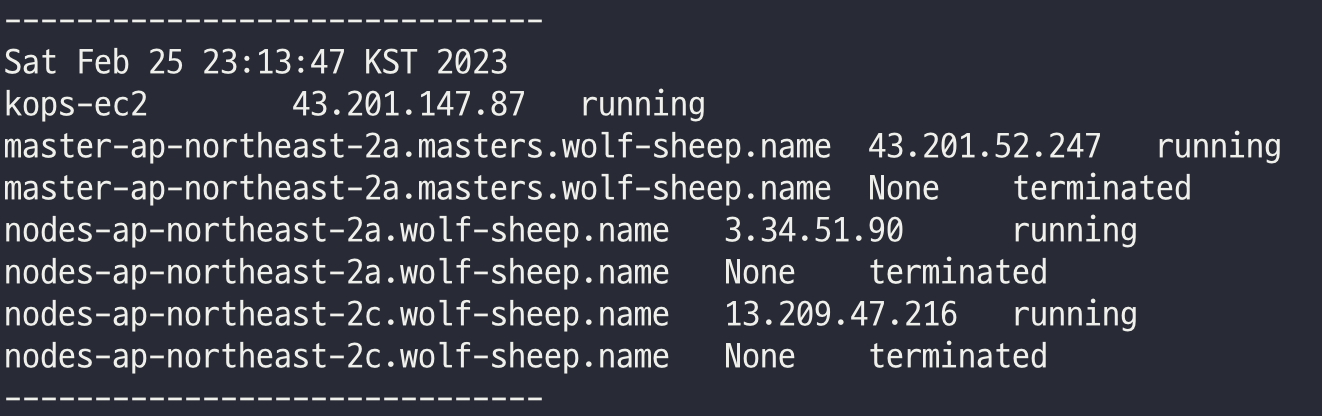
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --output text | sort; echo "------------------------------" ;date; sleep 1; done
# 인스턴스그룹 정보 확인
kops get ig
# 노드 추가
kops edit ig nodes-ap-northeast-2a --set spec.minSize=2 --set spec.maxSize=2
# 적용
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster
# 워커노드 증가 확인
while true; do kubectl get node; echo "------------------------------" ;date; sleep 1; done
그라파나 웹 접속 및 대시보드 추가 - TSDB 데이터를 시각화, 다양한 데이터 형식 지원
- 대시보드 사용 : 기본 대시보드 사용
- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- 확인해보자 - K8S / CR / Cluster, Node Exporter / Use Method / Cluster
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → Import → 13770 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Node Exporter Full] Dashboard → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
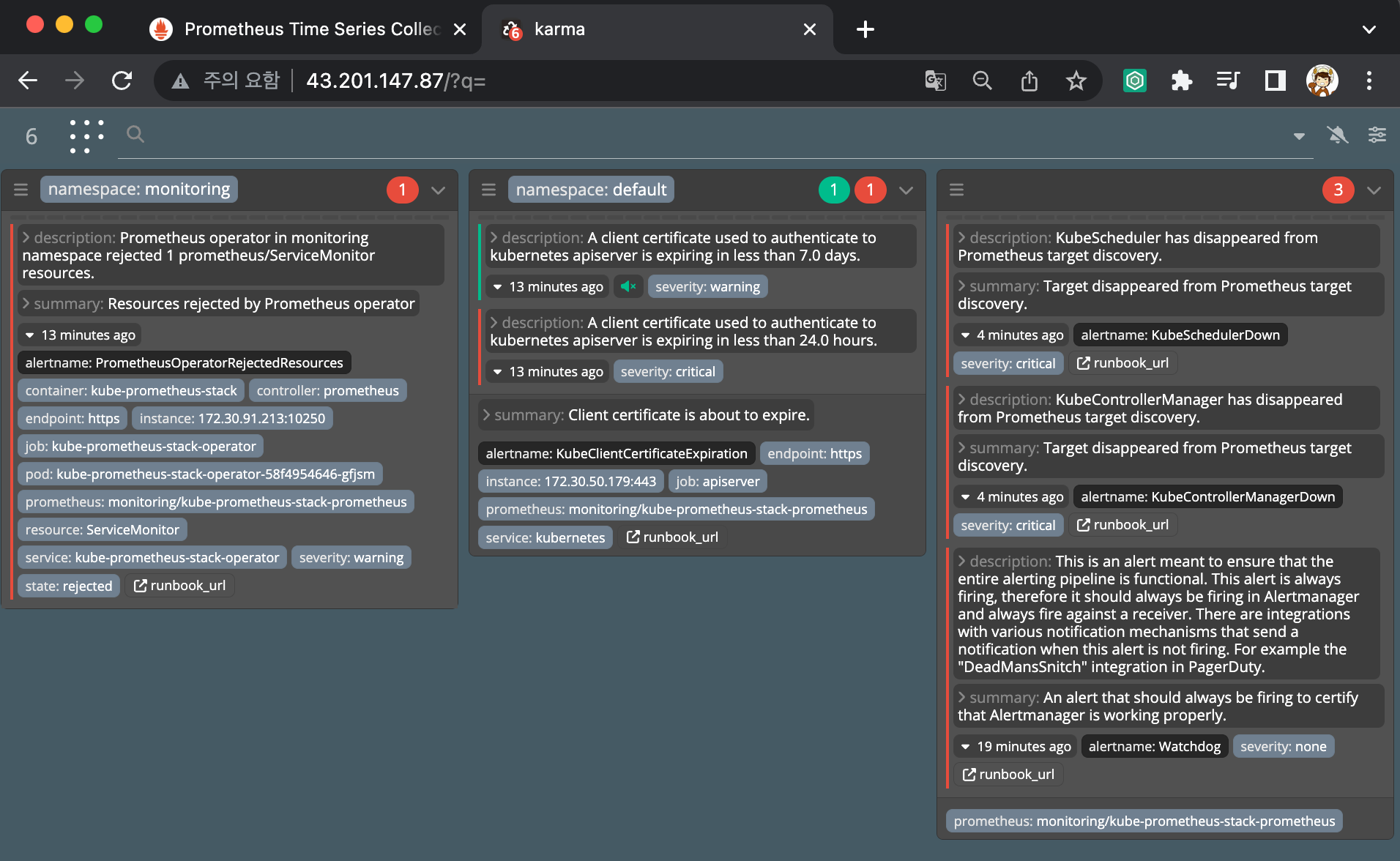
얼럿매니저 웹 접속 & 얼럿매니저 대시보드 karma 사용
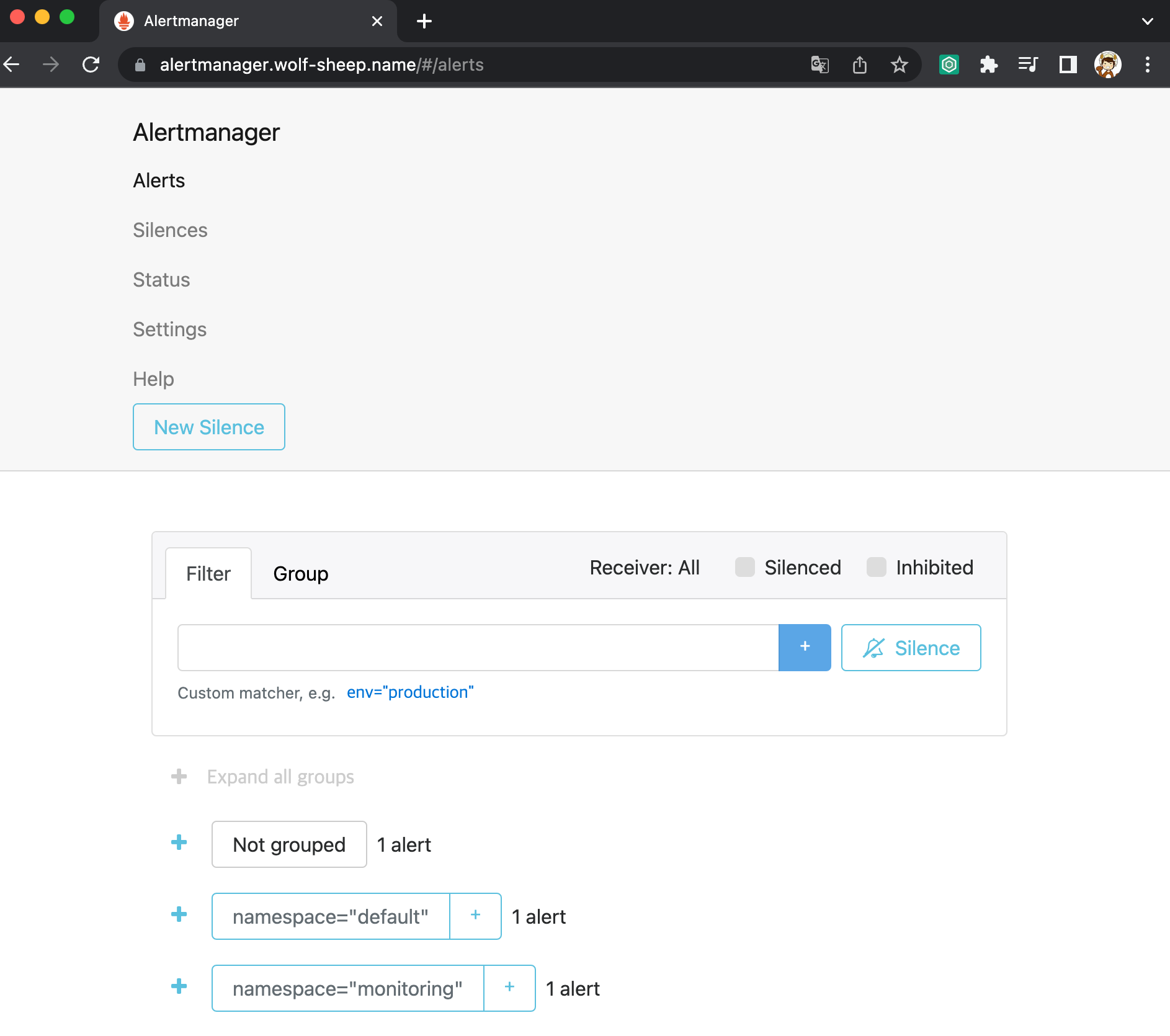
- Alerts 경고: 시스템 문제 시 프로메테우스가 전달한 경고 메시지 목록을 확인
- Silences 일시 중지 : 계획 된 장애 작업 시 일정 기간 동안 경고 메시지를 받지 않을 때, 메시지별로 경고 메시지를 일시 중단 설정
- Statue 상태 : 얼럿매니저 상세 설정 확인
얼럿매니저 대시보드 karma 컨테이너로 실행
# 실행
docker run -d -p 80:8080 -e ALERTMANAGER_URI=https://alertmanager.$KOPS_CLUSTER_NAME ghcr.io/prymitive/karma:latest
# 확인
docker ps
# 얼럿매니저 대시보드 karma 웹 접속 주소 확인
echo -e "karma Web URL = http://$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)"
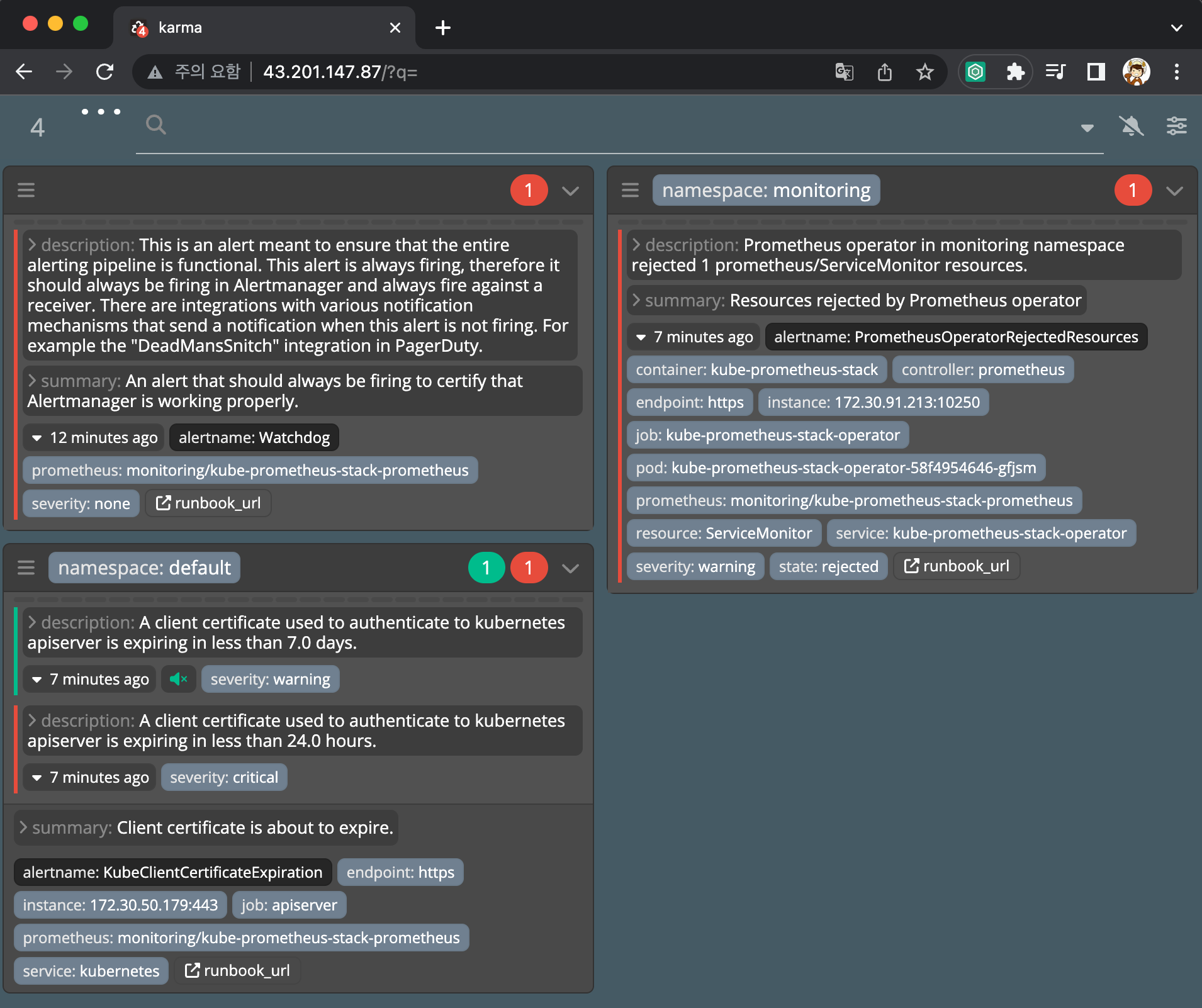
Alerting - 얼럿매니저
프로메테우스의 임곗값 도달 시 경고 메시지를 얼럿매니저에 푸시 이벤트로 전달하고, 얼럿매지저는 이를 가공후 이메일/슬랙 등에 전달
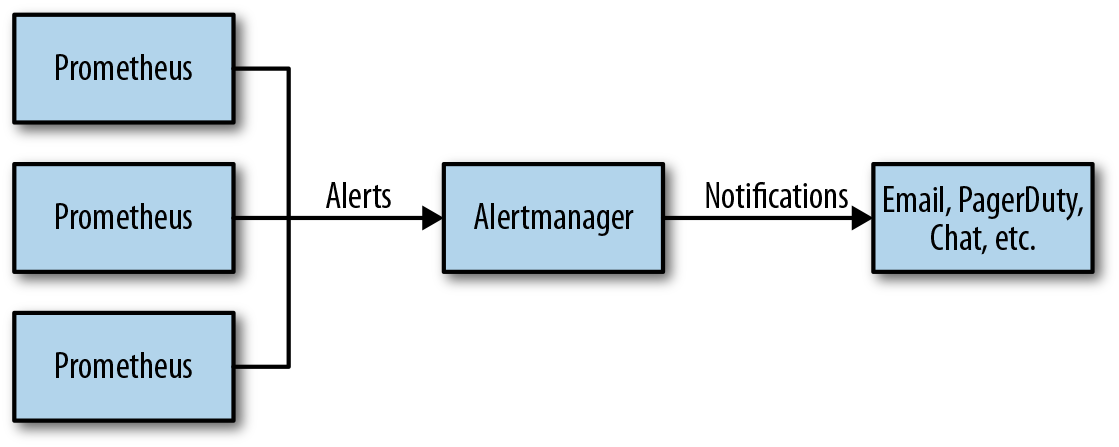
- Alerting rules in Prometheus servers send alerts to an Alertmanager.
- The Alertmanager then manages those alerts, including silencing, inhibition, aggregation and sending out notifications via methods such as email, on-call notification systems, and chat platforms.
- The Alertmanager handles alerts sent by client applications such as the Prometheus server.
- It takes care of deduplicating, grouping, and routing them to the correct receiver integration such as email, PagerDuty, or OpsGenie.
- It also takes care of silencing and inhibition of alerts.
프로메테우스 웹 Alert & 얼럿매니저 웹 karma
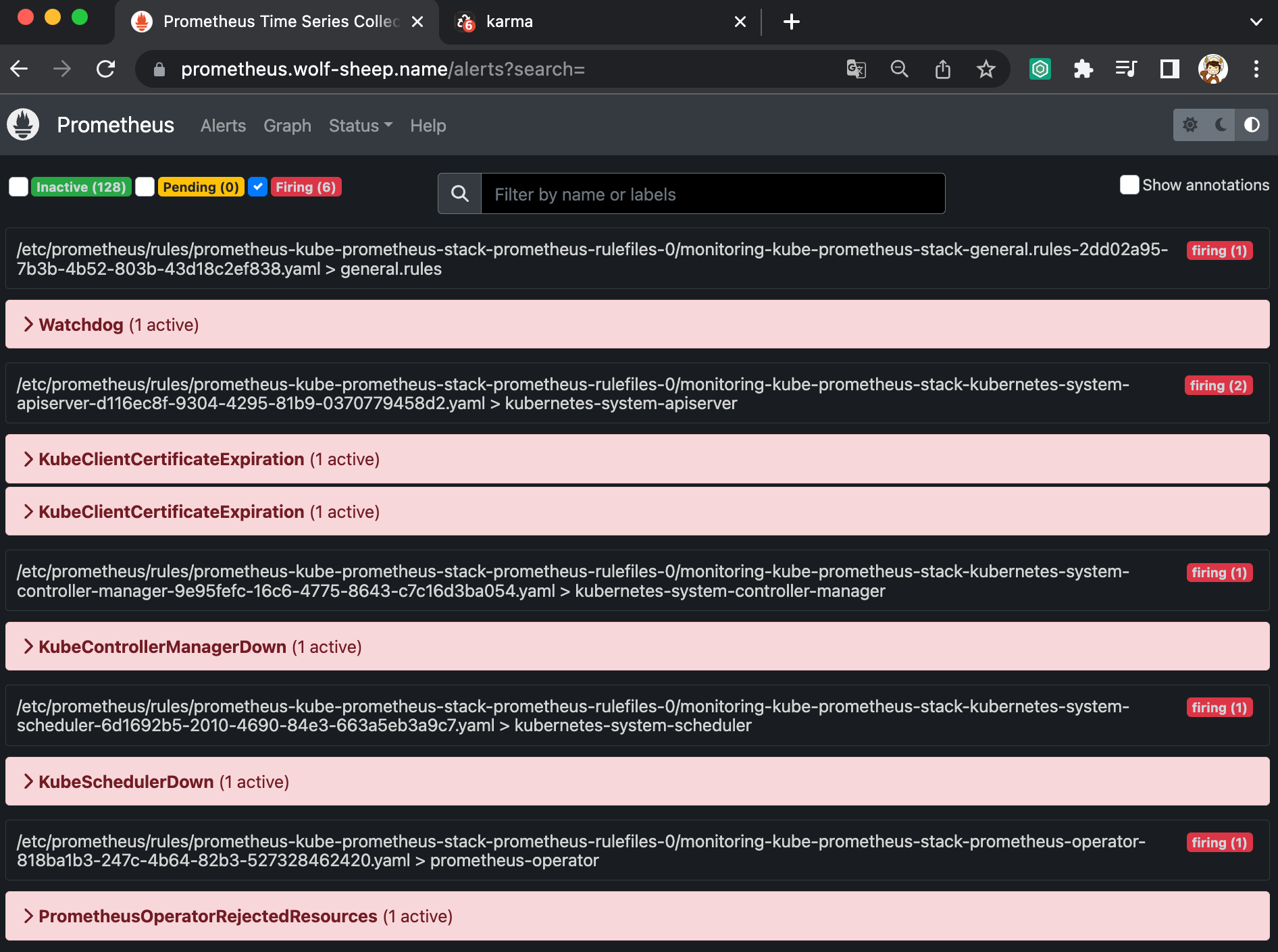
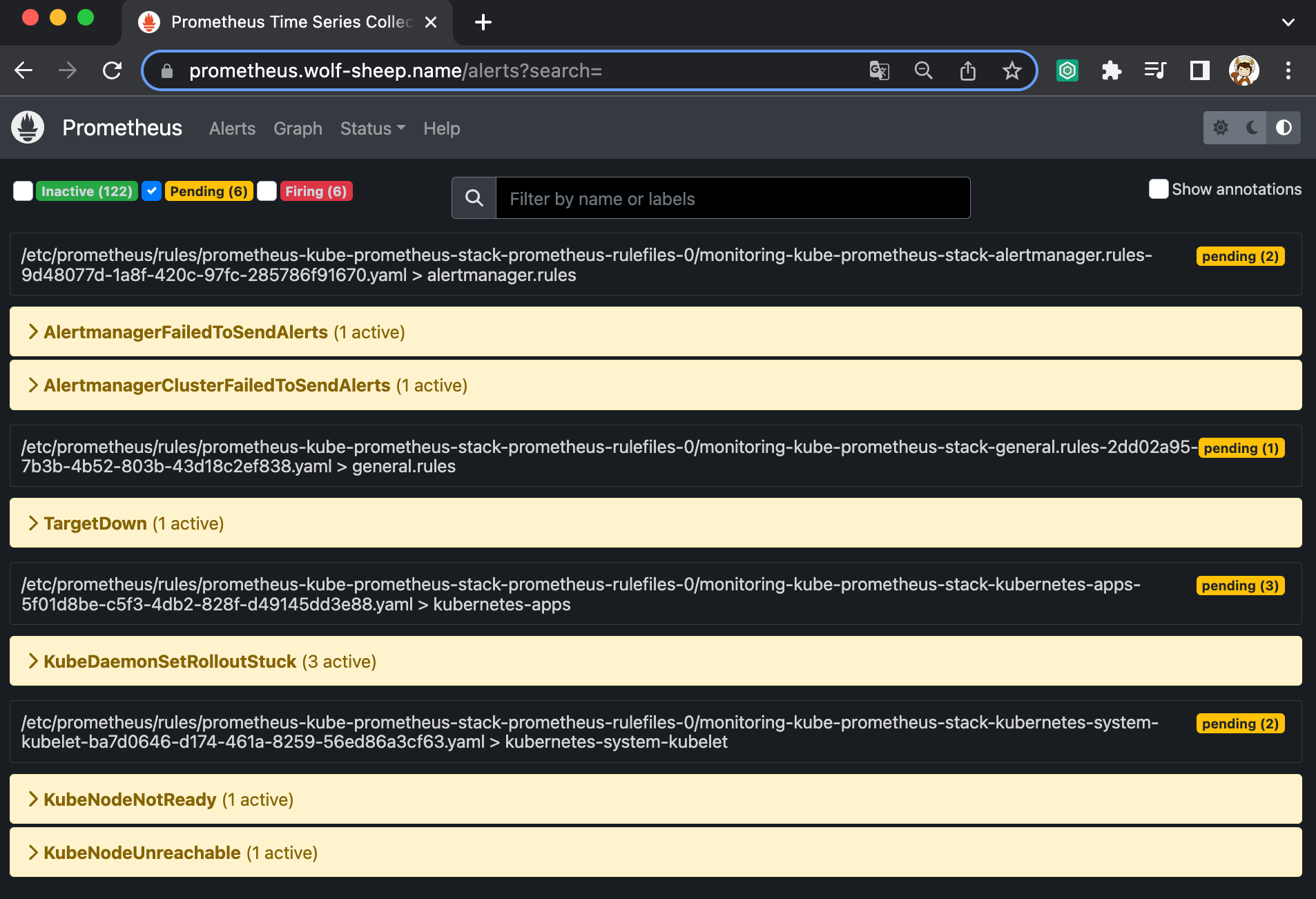
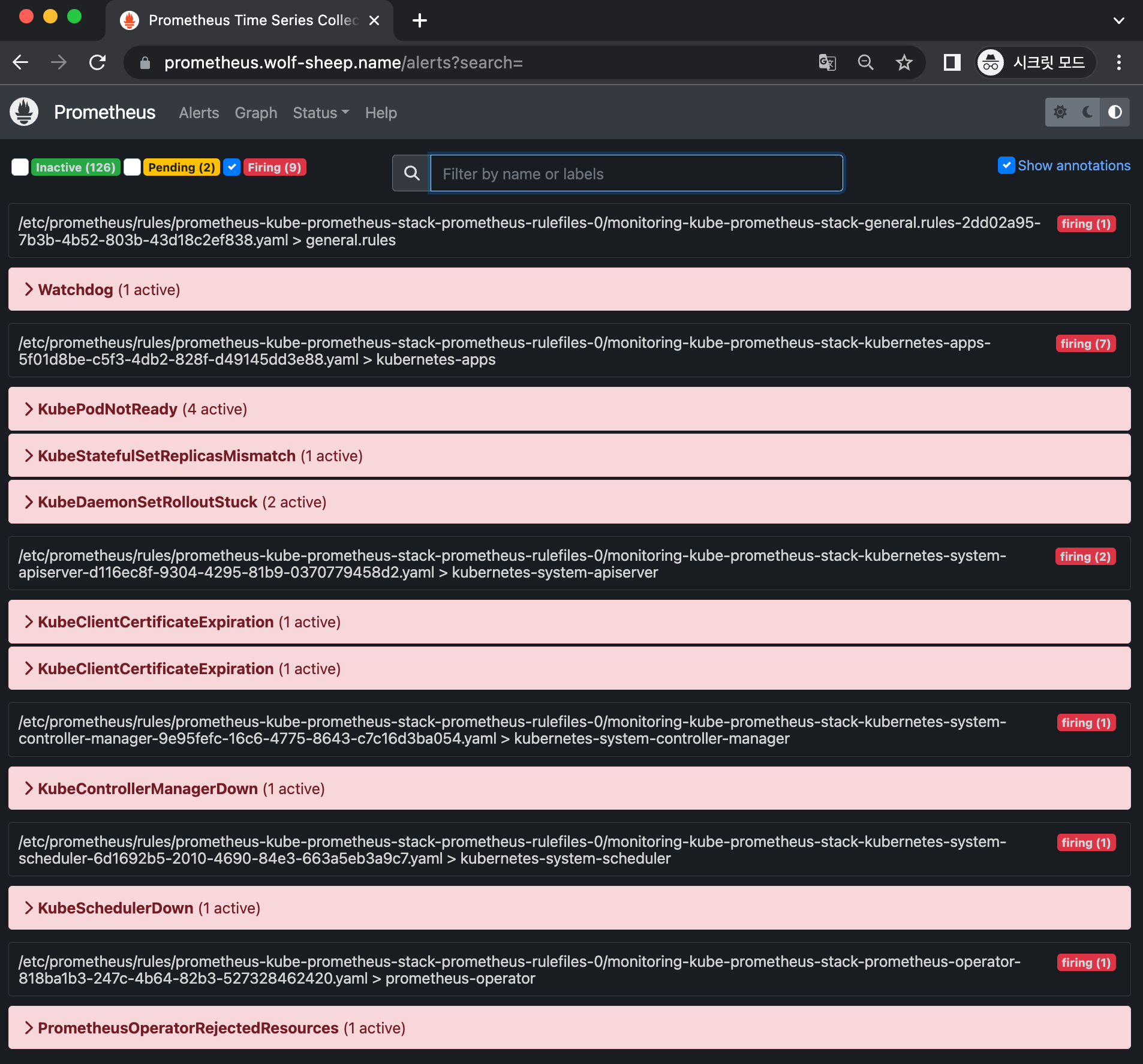
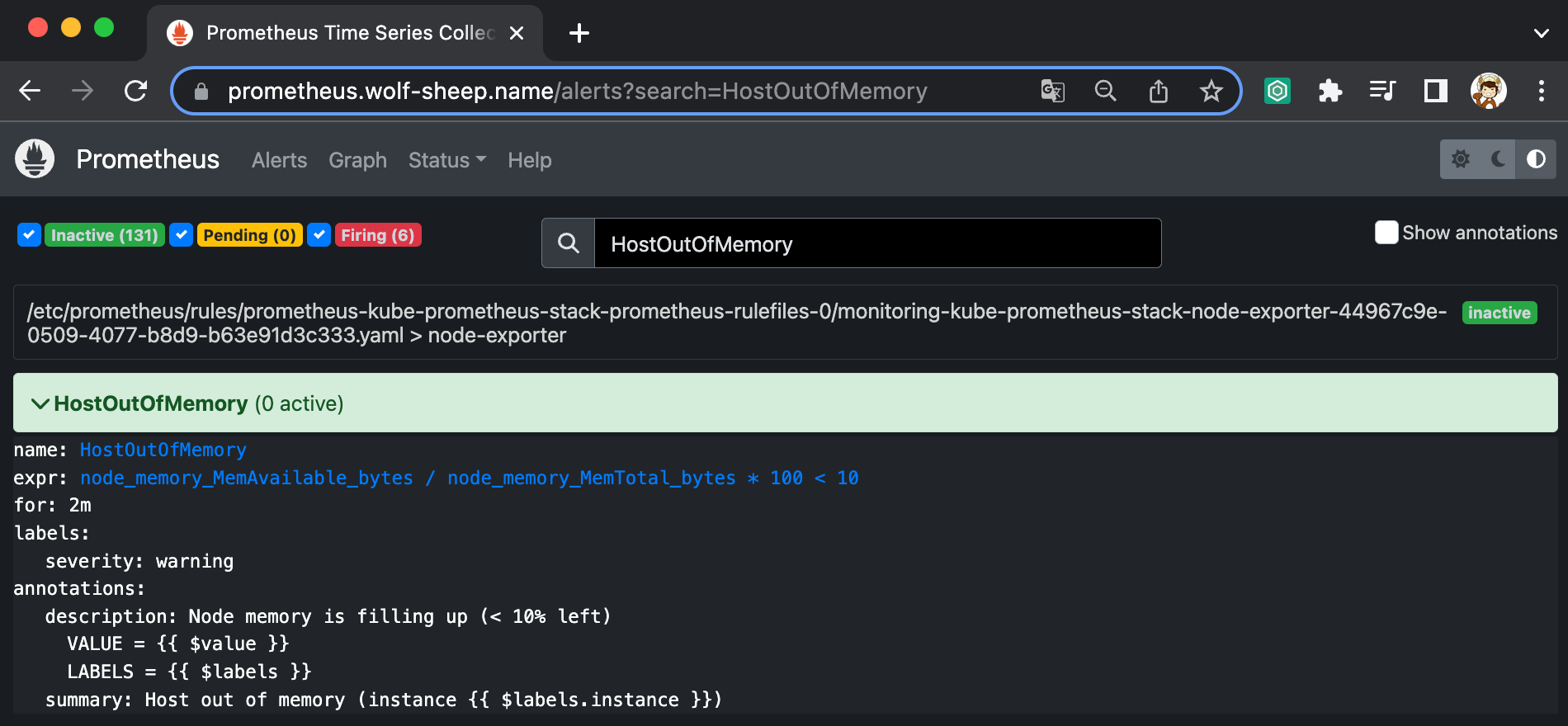
- 프로메테우스 웹 접속 후 상단 Alert 메뉴 확인 : 시스템 경고 정책은 prometheusrules CRD로 관리
- Inactive 비활성화 : prometheusrules 중 경고가 활성화되지 않은 정상적인 상태
- Pending 지연 : 설정한 임곗값을 초과해 경고 상황이지만 경고 메시지를 전달하기까지 임곗값 시간을 초과하지 않은 상태, 이를 통해 오탐과 자동 복구된 에러 메시지를 처리
- Firing 경보 : 임곗값과 임곗값 시간을 초과해서 경보가 발생한 메시지. 해당 메시지는 얼럿매니저에 전달되어 얼럿매지저를 통해 전파됨
# 프로메테우스 룰 확인
kubectl get prometheusrules -n monitoring
kubectl get prometheusrules -n monitoring kube-prometheus-stack-kubernetes-system-controller-manager -o json | jq
# 룰 전체 확인
kubectl get prometheusrules -n monitoring -o json | more
# 메트릭 이름 확인
kubectl get prometheusrules -n monitoring -o json | grep '"record":' | sed 's/^ *//'
kubectl get prometheusrules -n monitoring -o json | grep '"record":' | sed 's/^ *//' | wc -l
# 얼럿 이름 확인
kubectl get prometheusrules -n monitoring -o json | grep '"alert":' | sed 's/^ *//'
# 얼럿 갯수 확인
kubectl get prometheusrules -n monitoring -o json | grep '"alert":' | sed 's/^ *//' | wc -l
134
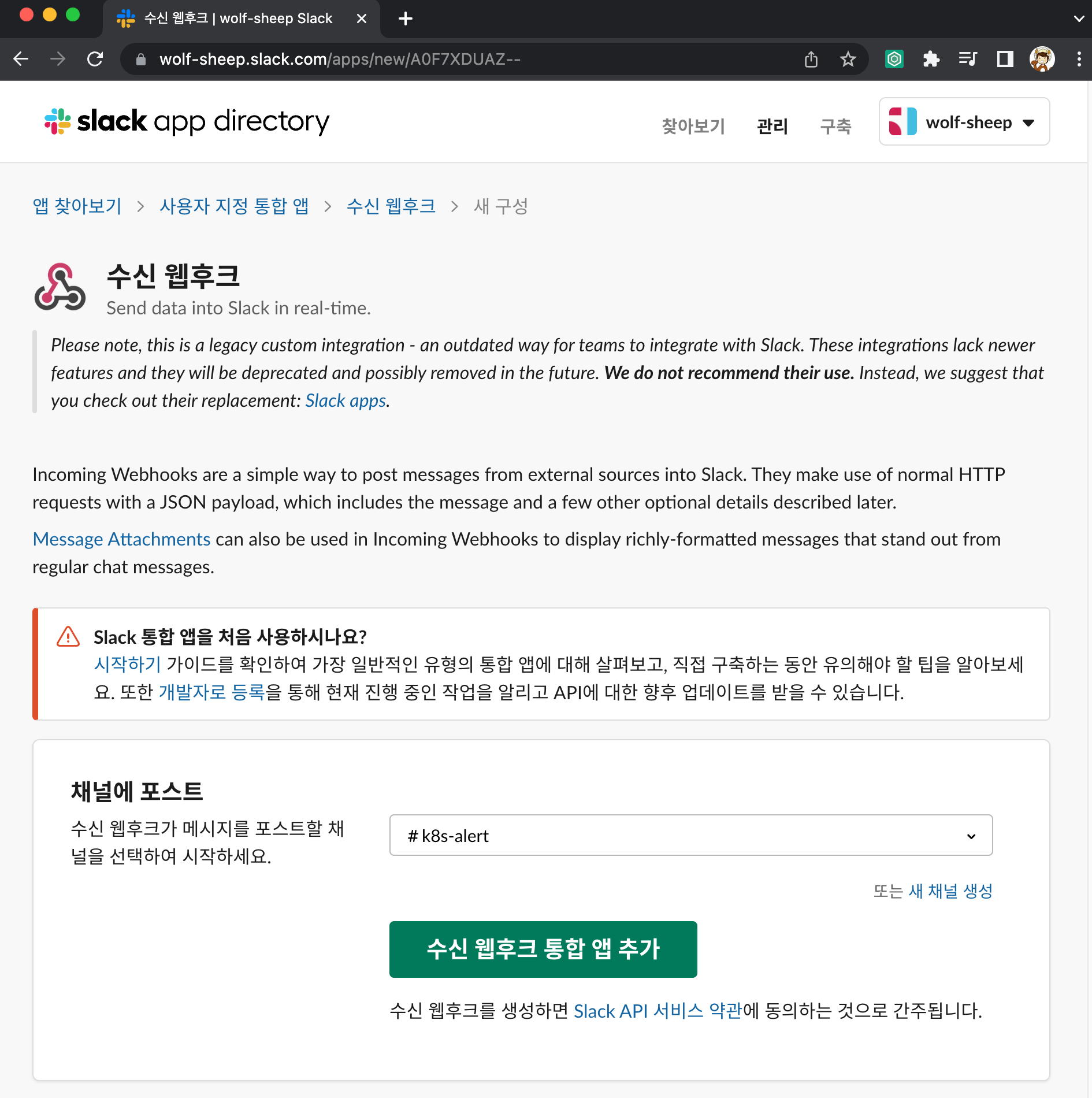
슬랙 채널 및 웹훅 URL 생성 및 얼럿매니저 설정 적용 (스터디 책 350~360 페이지 내용)
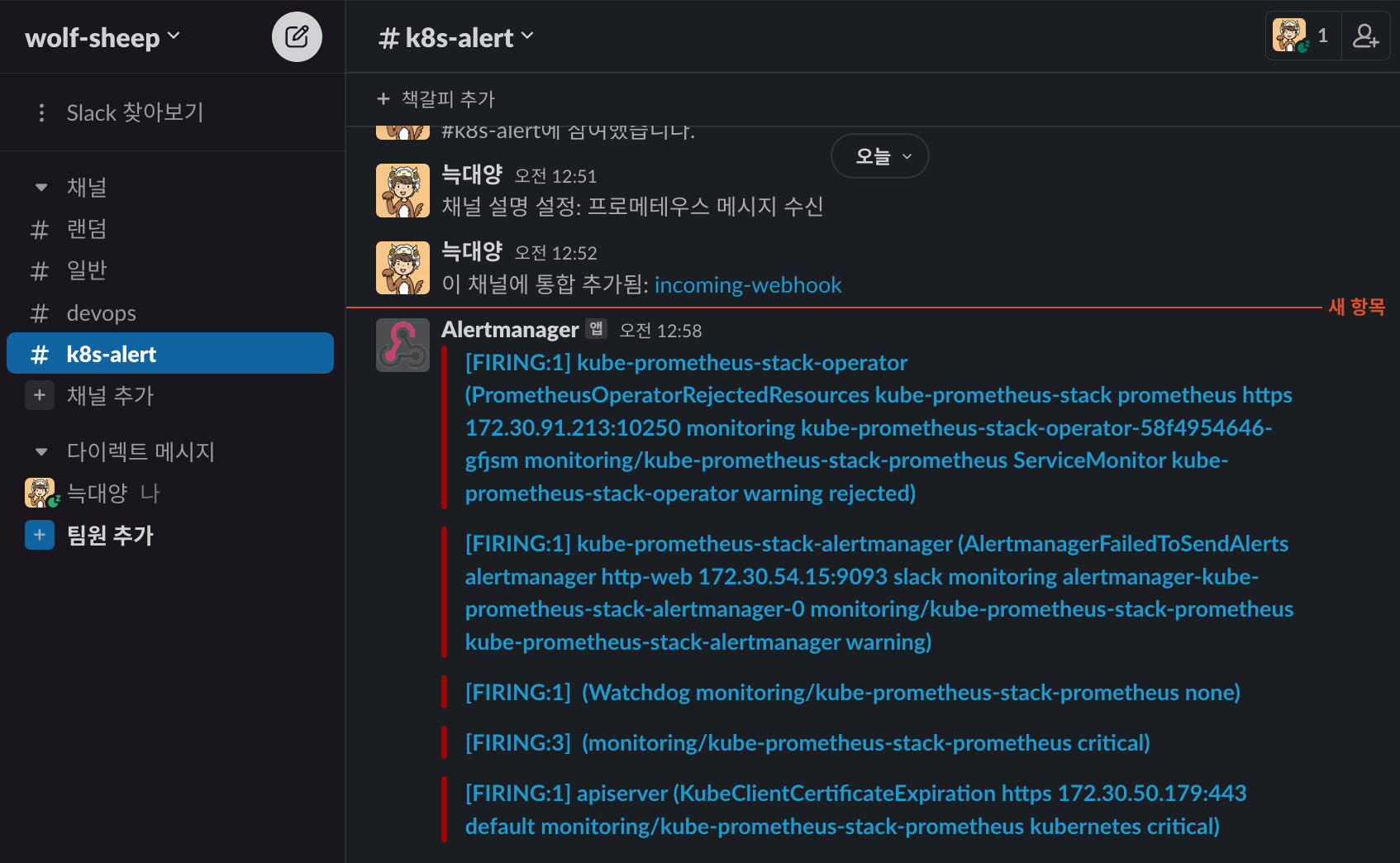
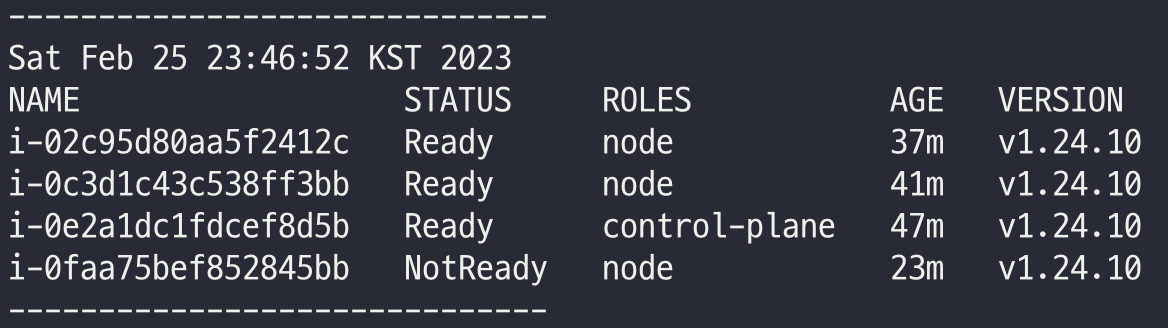
[장애 재현] 워커 노드 3번 kubelet down → 얼럿매니저 기능 검증 : 워커 노드 3번 다운 감지(TargetDown → Kube…)
# 모니터링
while true; do kubectl get node; echo "------------------------------" ;date; sleep 1; done
#
WNODE3=<자신의 워커노드 3번 퍼블릭 IP>
WNODE3=13.125.162.198
ssh -i ~/.ssh/id_rsa ubuntu@$WNODE3 hostname
# 워커노드 3번 kubelet 강제 stop
ssh -i ~/.ssh/id_rsa ubuntu@$WNODE3 sudo systemctl stop kubelet
ssh -i ~/.ssh/id_rsa ubuntu@$WNODE3 sudo systemctl status kubelet

Grafana Alert
PLG 스택
NGINX 웹서버 배포
# 헬름 리포지토리 추가
helm repo add bitnami https://charts.bitnami.com/bitnami
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm install nginx bitnami/nginx --version 13.2.27 -f nginx-values.yaml
# CLB에 ExternanDNS 로 도메인 연결
kubectl annotate service nginx "external-dns.alpha.kubernetes.io/hostname=nginx.$KOPS_CLUSTER_NAME"
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
# nginx 파드내에 컨테이너 갯수 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
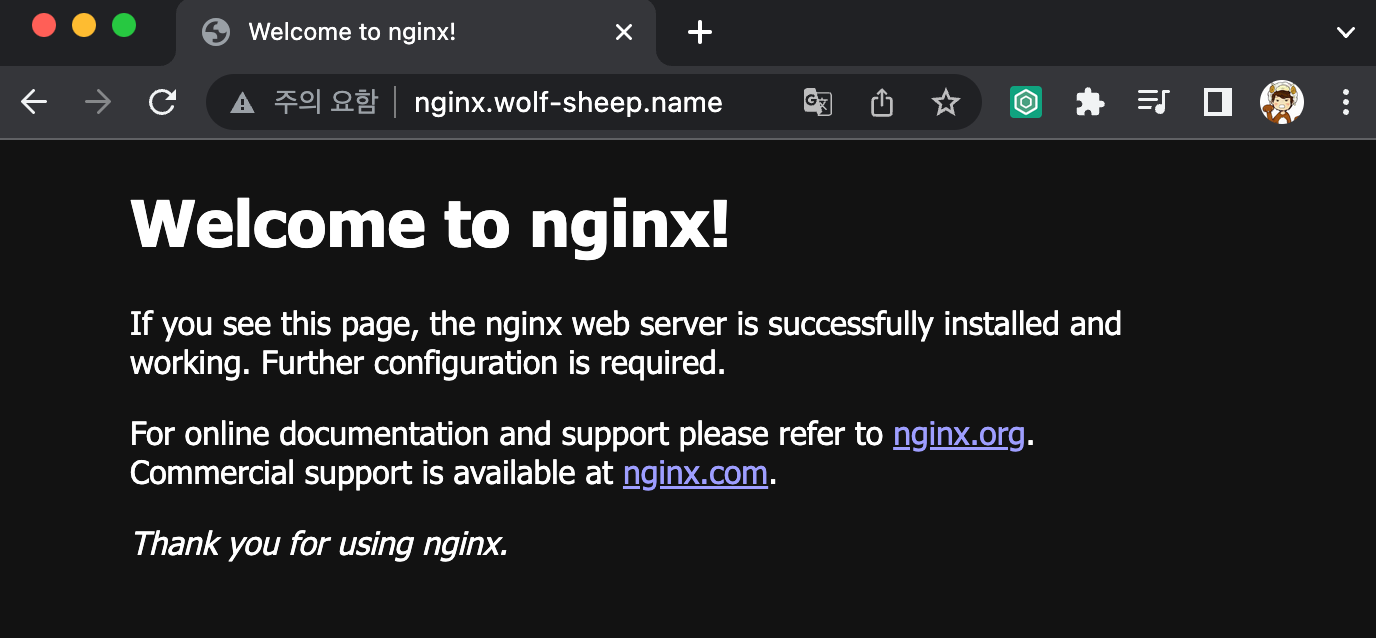
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = http://nginx.$KOPS_CLUSTER_NAME"
curl -s http://nginx.$KOPS_CLUSTER_NAME
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s http://nginx.$KOPS_CLUSTER_NAME -I | head -n 1; date; sleep 1; done
# (참고) 삭제 시
helm uninstall nginx
컨테이너 로그 환경의 로그는 표준 출력 stdout과 표준 에러 stderr로 보내는 것을 권고
- 해당 권고에 따라 작성된 컨테이너 애플리케이션의 로그는 해당 파드 안으로 접속하지 않아도 사용자는 외부에서 kubectl logs 명령어로 애플리케이션 종류에 상관없이, 애플리케이션마다 로그 파일 위치에 상관없이, 단일 명령어로 조회 가능
# 로그 모니터링
kubectl logs deploy/nginx -c nginx -f
# nginx 웹 접속 시도
# 컨테이너 로그 파일 위치 확인
kubectl exec -it deploy/nginx -c nginx -- ls -l /opt/bitnami/nginx/logs/
total 0
lrwxrwxrwx 1 root root 11 Feb 18 13:35 access.log -> /dev/stdout
lrwxrwxrwx 1 root root 11 Feb 18 13:35 error.log -> /dev/stderr
PLG Stack 소개

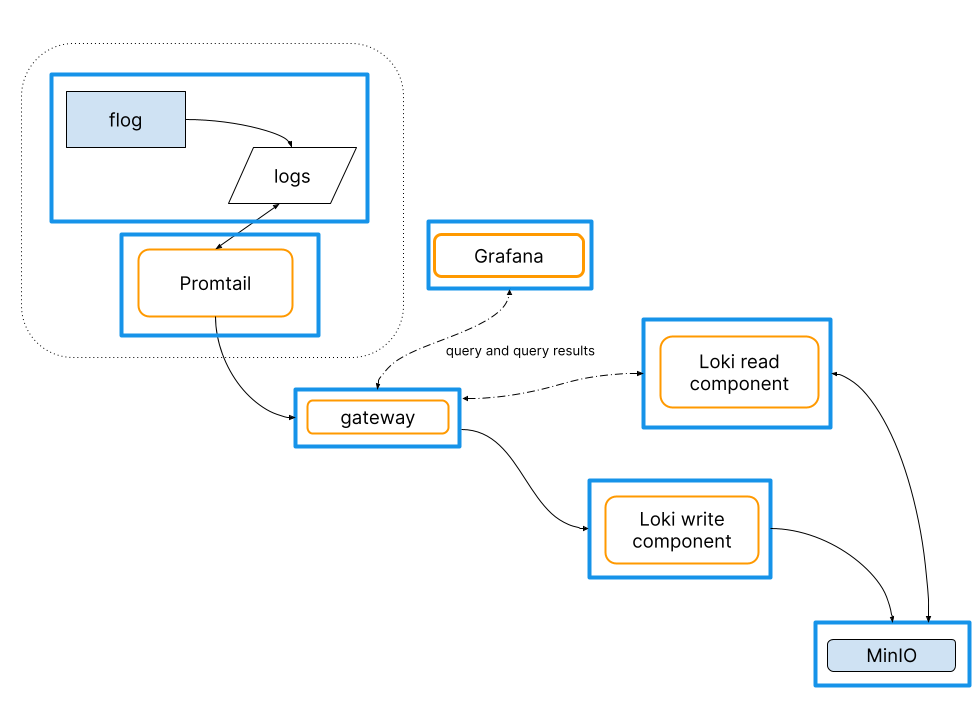
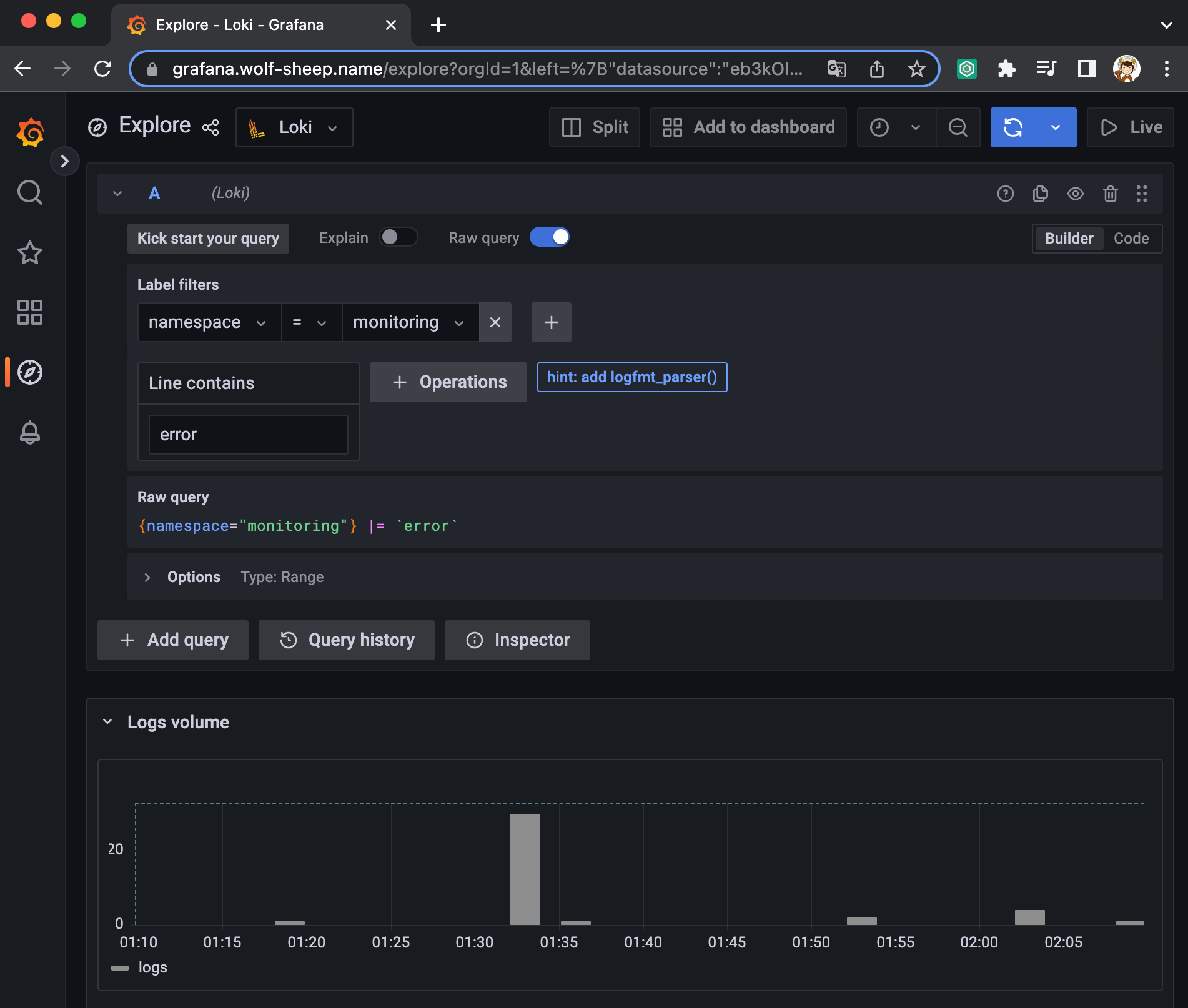
Promtail + Loki + Grafana 여러 파드의 로그들을 중앙 서버에 저장하고 이를 조회
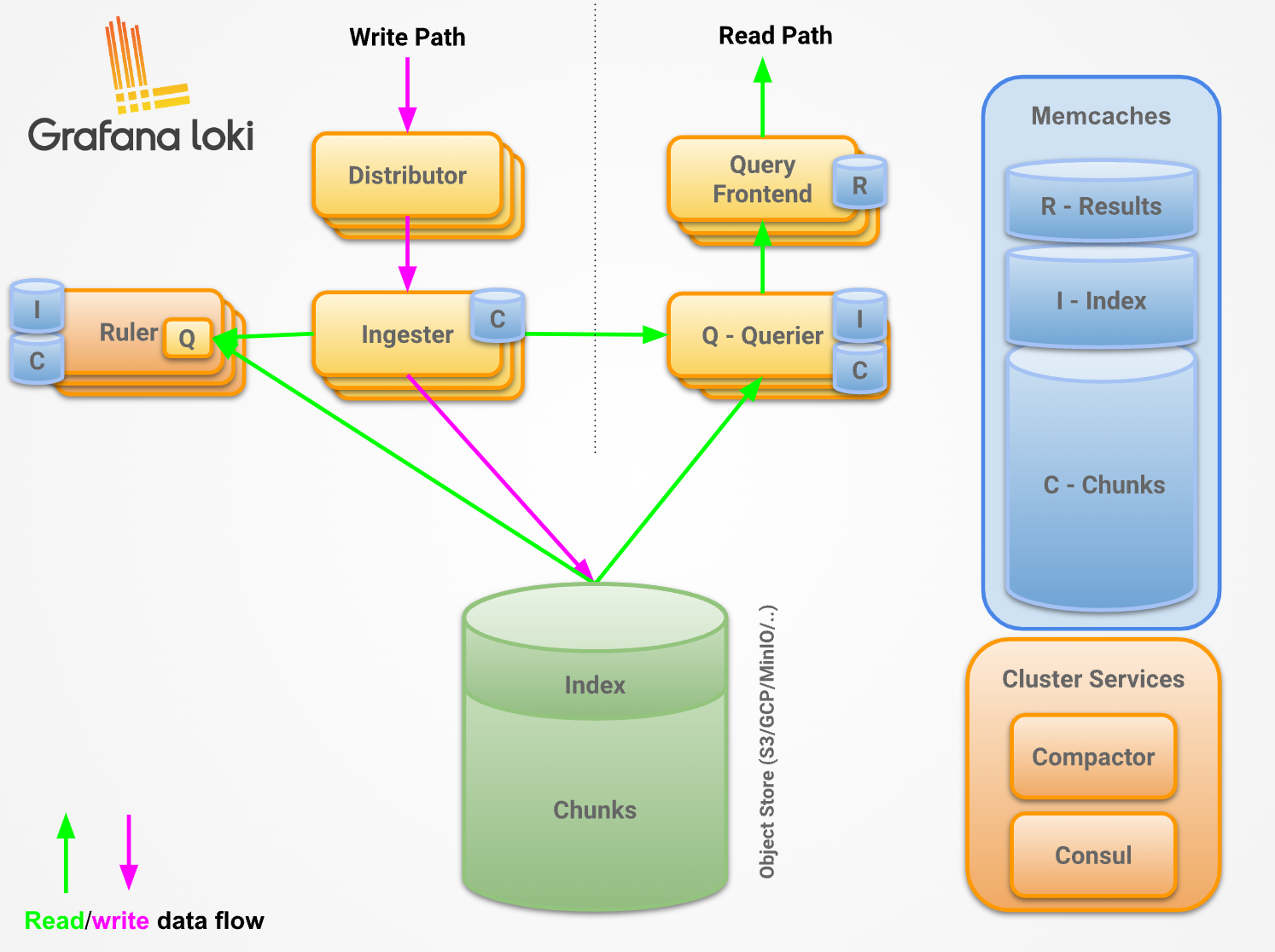
- Loki에 저장한 로그는 LogQL(PromQL과 유사)을 이용해 조회 할 수 있으며, 그라파나 웹이나 logcli를 이용해 조회 가능
- 전체 로그 기반 인덱스를 생성하지 않고, 메타데이터를 기준으로 인덱스를 생성하여 자원 사용량이 현저히 적음
- Promtail은 데몬셋으로 실행되며 각 로그에 로그를 중앙 로키 서버에 전달, Promtail 외에도 도커, FluentD 등 다른 로그수집 에이전트 사용 할 수 있다
Loki & Promtail - 헬름 차트를 활용하여 설치
Loki 설치
# 모니터링
kubectl create ns loki
watch kubectl get pod,pvc,svc,ingress -n loki
# Repo 추가
helm repo add grafana https://grafana.github.io/helm-charts
# 파라미터 설정 파일 생성
cat <<EOT > ~/loki-values.yaml
persistence:
enabled: true
size: 20Gi
serviceMonitor:
enabled: true
EOT
# 배포
helm install loki grafana/loki --version 2.16.0 -f loki-values.yaml --namespace loki
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts -n loki
kubectl get-all -n loki
kubectl get servicemonitor -n loki
kubectl krew install df-pv && kubectl df-pv
# curl 테스트 용 파드 생성
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
# 로키 gateway 접속 확인
kubectl exec -it pod-1 -- curl -s http://loki.loki.svc:3100/api/prom/label
# (참고) 삭제 시
helm uninstall loki -n loki
kubectl delete pvc -n loki --all
Promtail 설치
# 파라미터 설정 파일 생성
cat <<EOT > ~/promtail-values.yaml
serviceMonitor:
enabled: true
config:
serverPort: 3101
clients:
- url: http://loki-headless:3100/loki/api/v1/push
#defaultVolumes:
# - name: pods
# hostPath:
# path: /var/log/pods
EOT
# 배포
helm install promtail grafana/promtail --version 6.0.0 -f promtail-values.yaml --namespace loki
# (참고) 파드 로그는 /var/log/pods에 저장
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME ls /var/log/pods
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts,servicemonitor -n loki
kubectl get-all -n loki
# (참고) 삭제 시
helm uninstall promtail -n loki
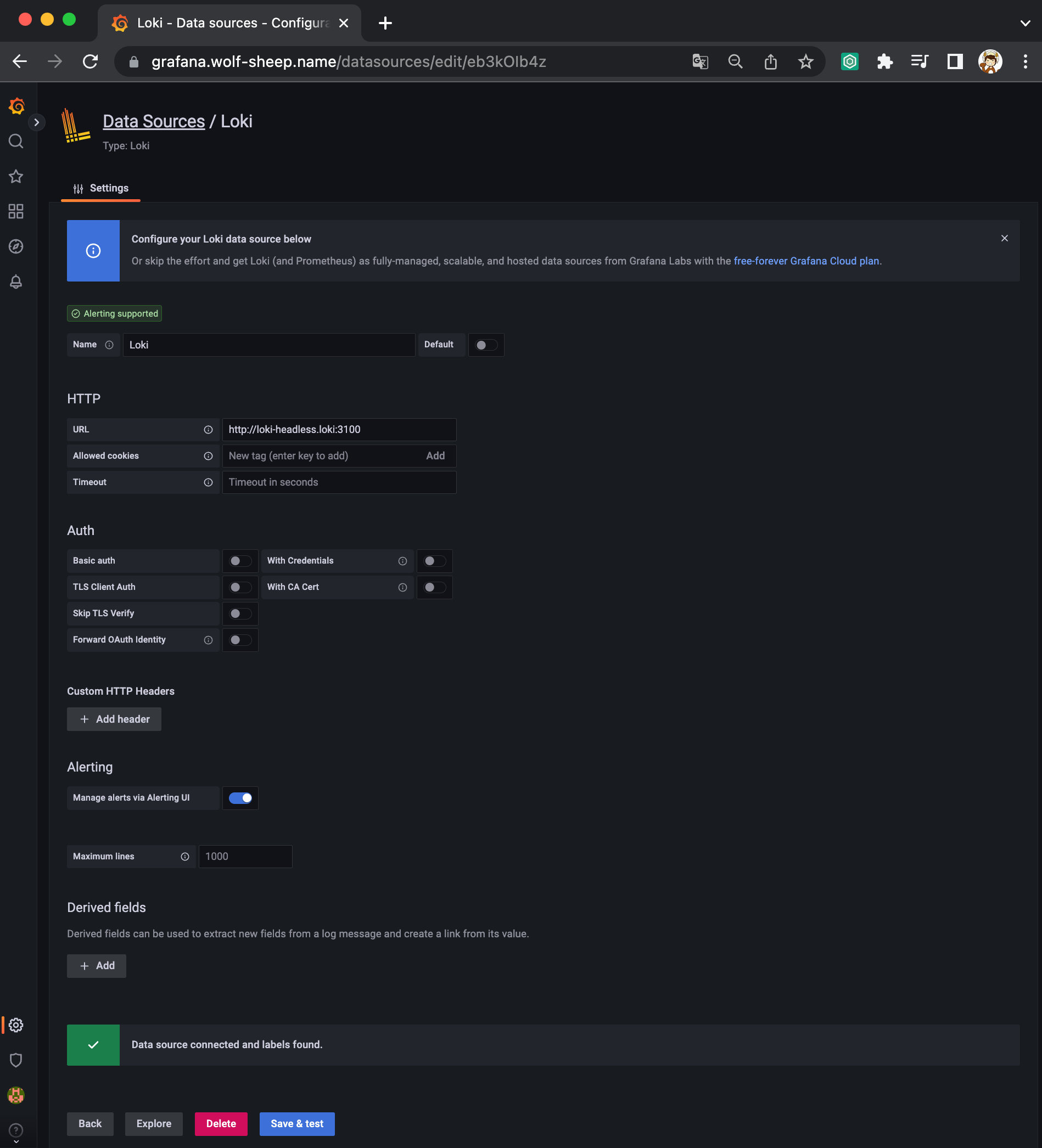
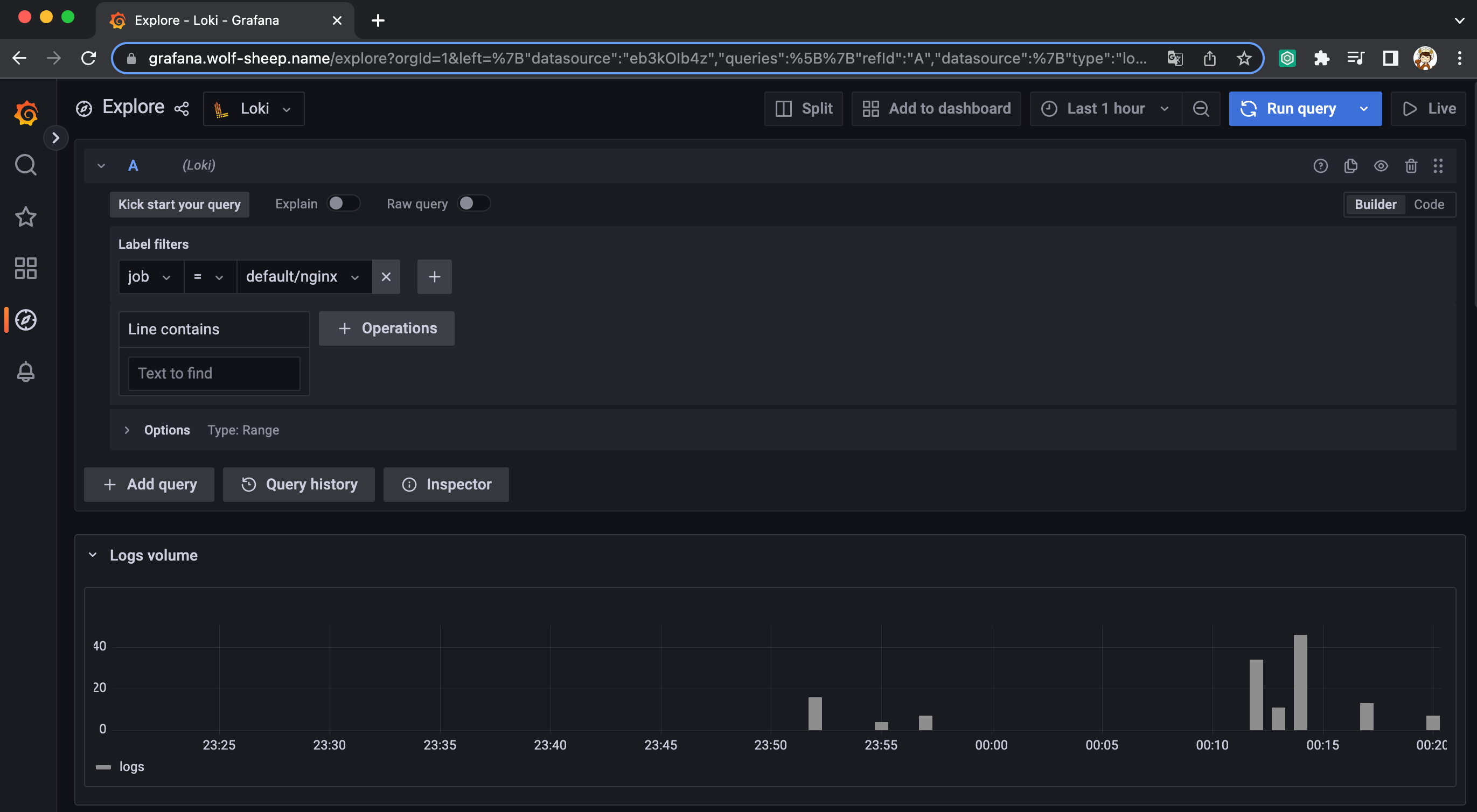
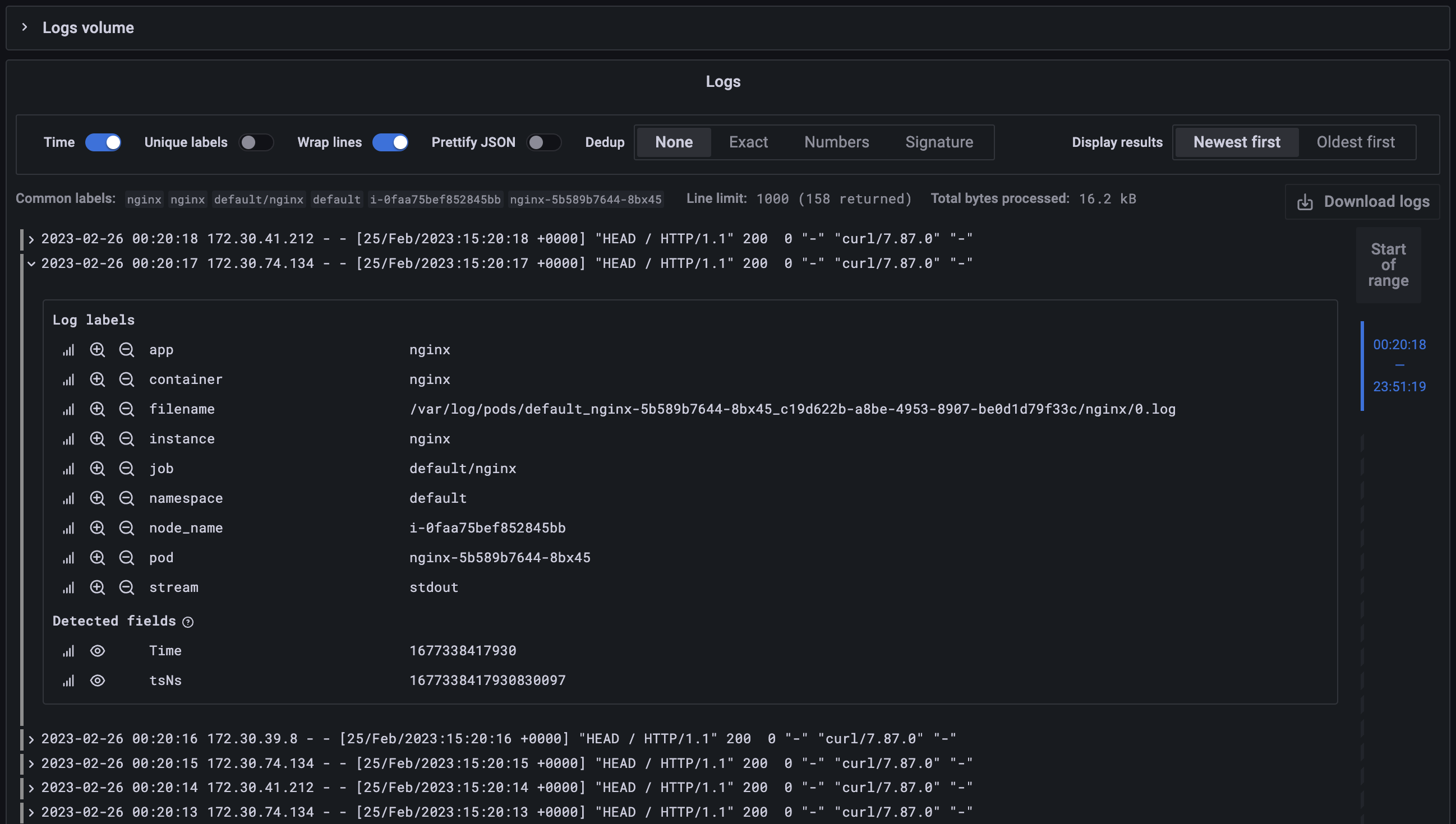
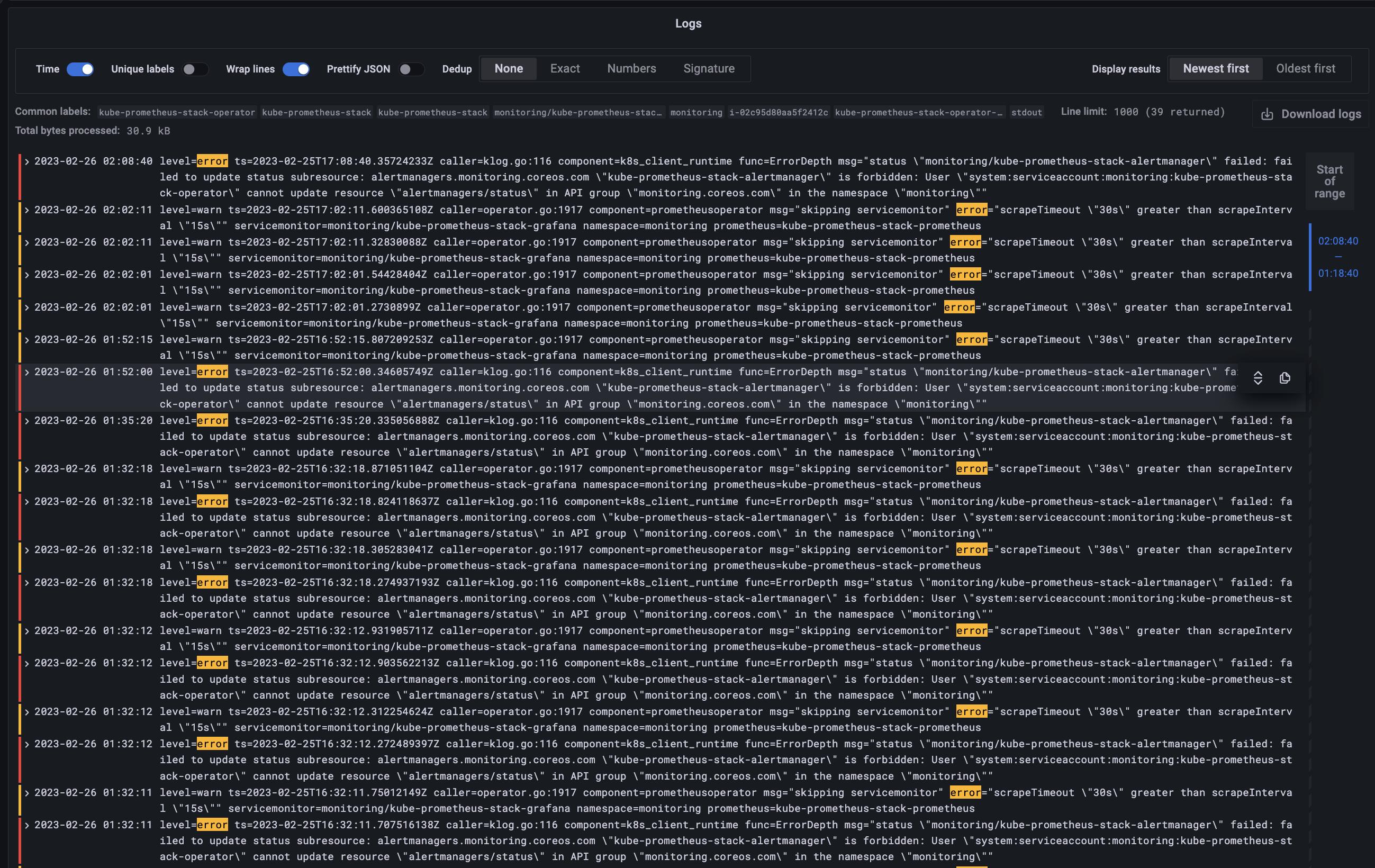
그라파나에서 로그 확인
- 그라파나 → Configuration → Data Source : 데이터 소스 추가 ⇒ Loki 클릭
- HTTP URL: http://loki-headless.loki:3100 ⇒ Save & Test
- nginx 반복 접속
(실습 완료 후) 자원 삭제
헬름 차트 삭제
# nginx 삭제
helm uninstall nginx
# promtail 삭제
helm uninstall promtail -n loki
# loki 삭제
helm uninstall loki -n loki
kubectl delete pvc -n loki --all
# 프로메테우스 스택 삭제
helm uninstall -n monitoring kube-prometheus-stack
kOps 클러스터 삭제 & AWS CloudFormation 스택 삭제
kops delete cluster --yes && aws cloudformation delete-stack --stack-name mykops
과제
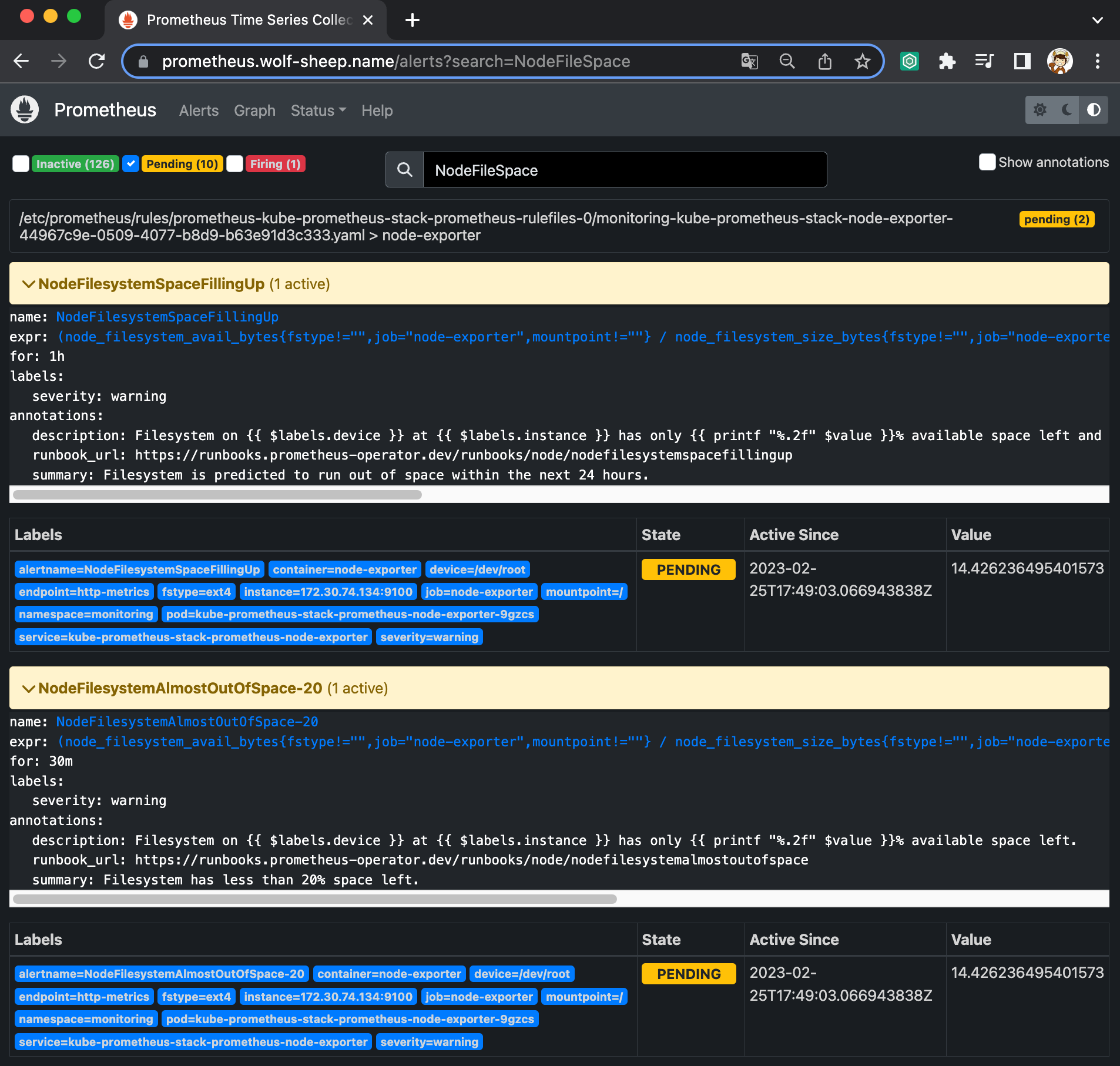
과제 1. 책 367~372페이지 - 사용자 정의 prometheusrules 정책 설정 : 파일 시스템 사용률 80% 초과 시 시스템 경고 발생시키기 ⇒ 직접 실습 후 관련 스샷을 올려주세요
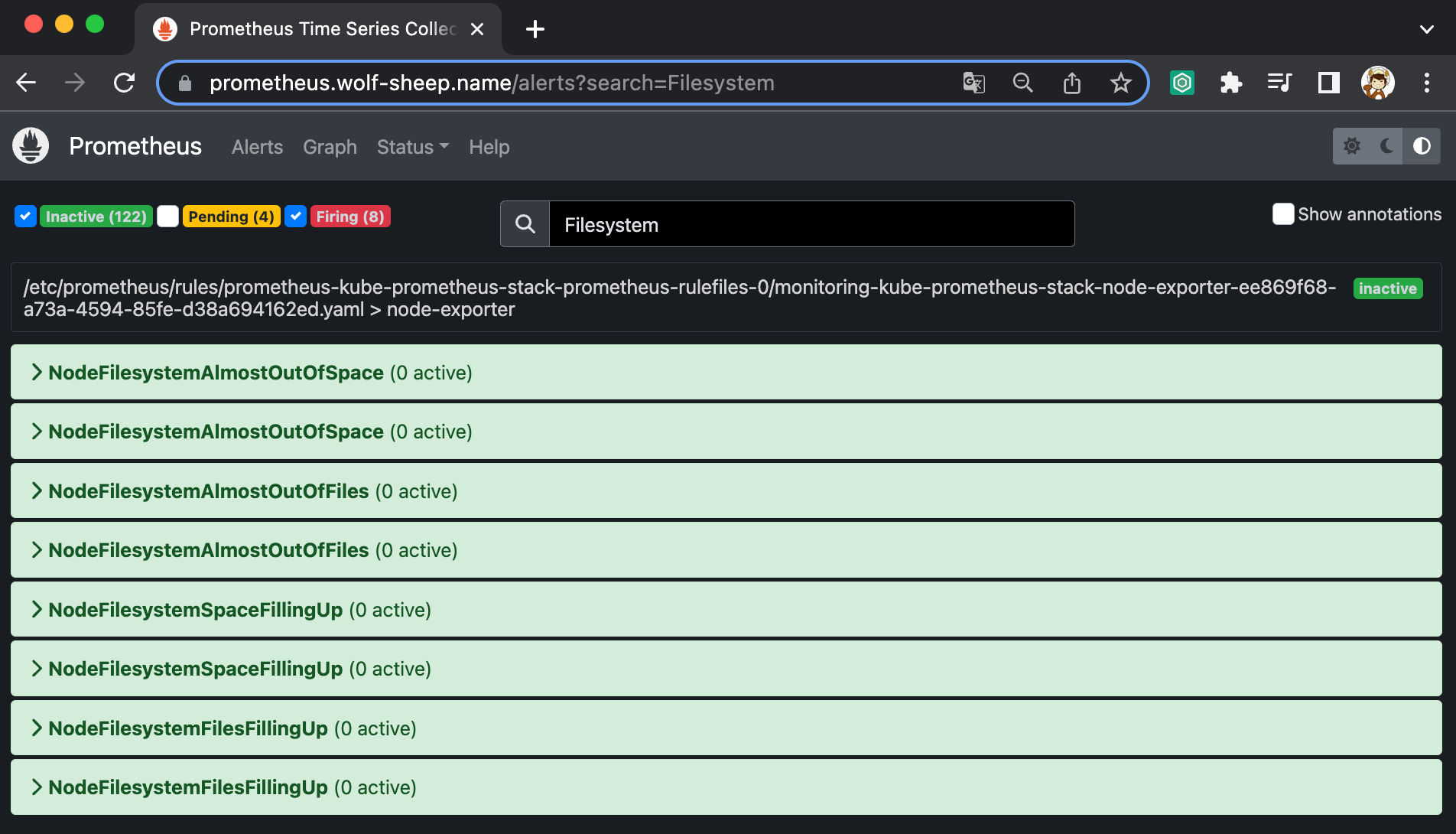

# yaml 파일 추출
k get prometheusrules.monitoring.coreos.com -n monitoring kube-prometheus-stack-node-exporter -o yaml > node-exporter-prometheusrule.yaml
# 아래와 같이 수정 진행
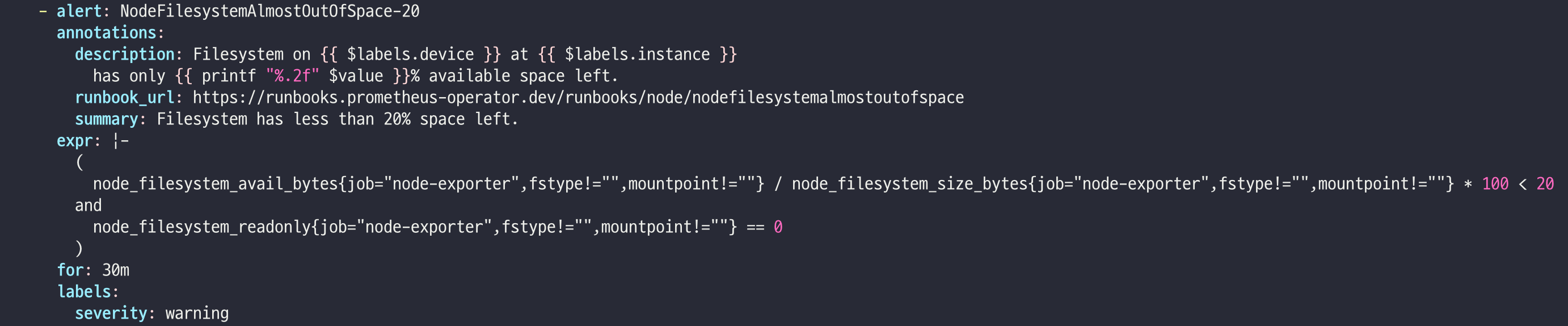
- alert: NodeFilesystemAlmostOutOfSpace-20
annotations:
description: Filesystem on {{ $labels.device }} at {{ $labels.instance }}
has only {{ printf "%.2f" $value }}% available space left.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemalmostoutofspace
summary: Filesystem has less than 20% space left.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 20
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
for: 10m
labels:
severity: warning
# yaml 파일 수정 후, 적용
# monitoring namespace에서 명령어 사용
# namespace 전환 예시
# kubectl config set-context --current --namespace=monitoring
kubectl apply -f node-exporter-prometheusrule.yaml
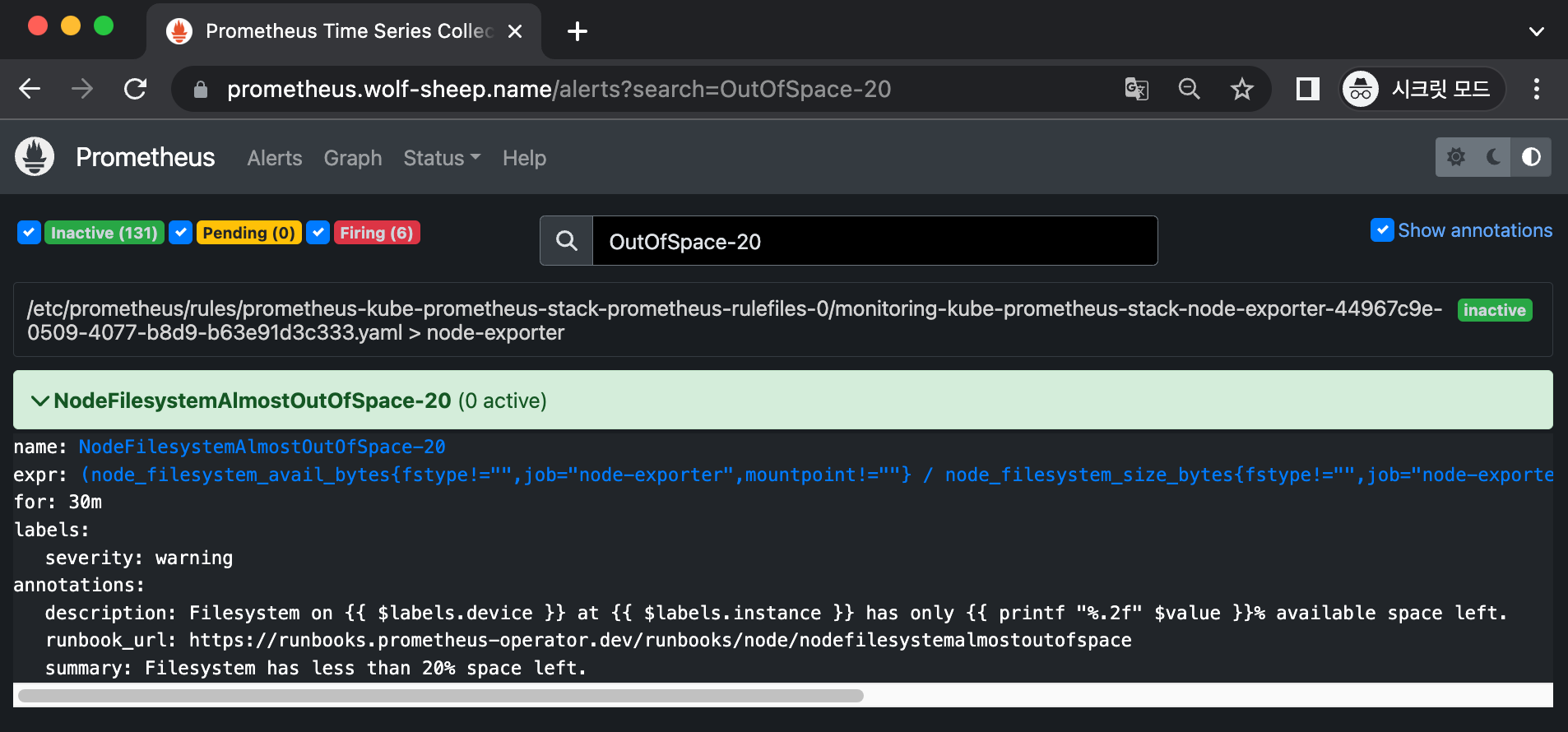
name: NodeFilesystemAlmostOutOfSpace-20
expr: (node_filesystem_avail_bytes{fstype!="",job="node-exporter",mountpoint!=""} / node_filesystem_size_bytes{fstype!="",job="node-exporter",mountpoint!=""} * 100 < 20 and node_filesystem_readonly{fstype!="",job="node-exporter",mountpoint!=""} == 0)
for: 30m
labels:
severity: warning
annotations:
description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemalmostoutofspace
summary: Filesystem has less than 20% space left.
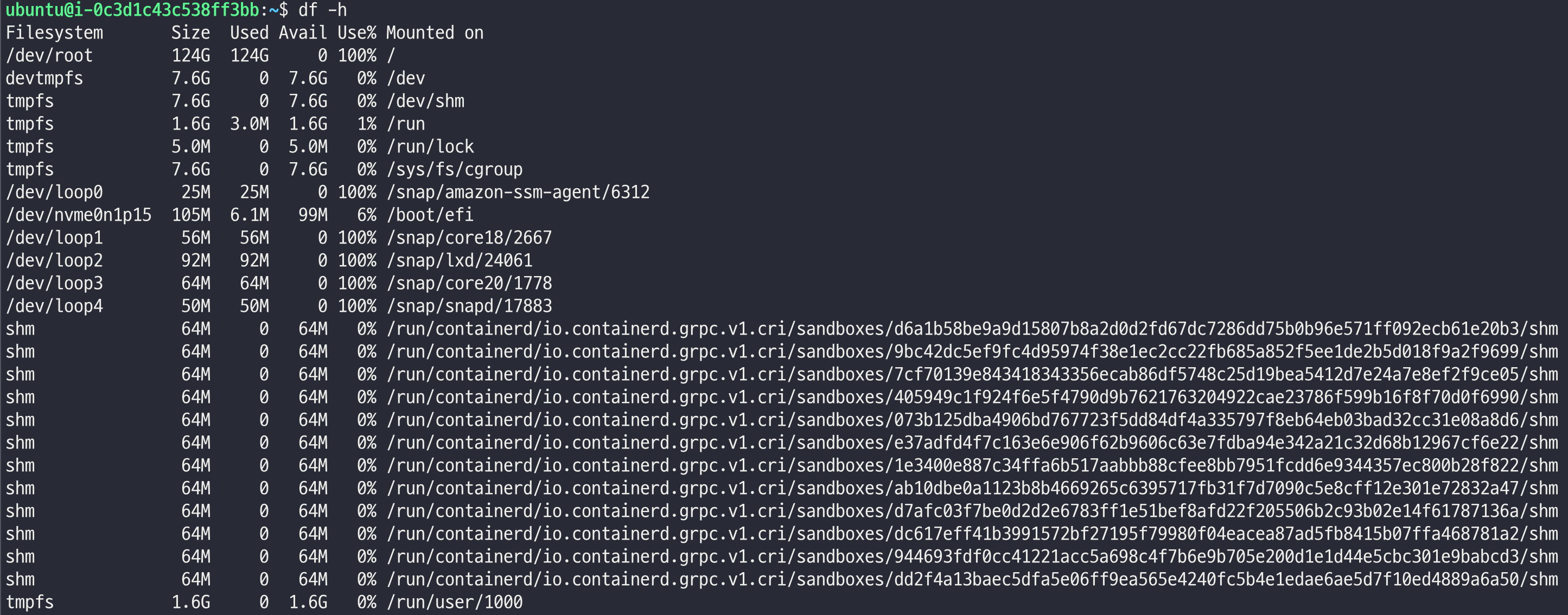
# 볼륨 맥스 찍기
sudo fallocate /var/10g -l 10g
sudo fallocate /var/10g -l 100g
과제 2. 책 386~389페이지 - LogQL 사용법 익히기 ⇒ 직접 실습 후 관련 스샷을 올려주세요

과제 3. 아래 1,2 과제 중 하나를 해주시면 됩니다
Awesome Prometheus alerts 를 참고해서 스터디에서 배우지 않은 Alert Rule 생성 및 적용 후 관련 스샷을 올려주세요



긴 글 읽어주셔서 감사합니다 🤗
'k8s > CloudNet@' 카테고리의 다른 글
| [CloudNet@] AWS EKS Workshop Study - 1주차. (0) | 2023.04.30 |
|---|---|
| [CloudNet@] Production Kubernetes Online Study - 7주차. (a.k.a FINAL) (0) | 2023.03.05 |
| [CloudNet@] Production Kubernetes Online Study - 5주차. (3) | 2023.02.19 |
| [CloudNet@] Production Kubernetes Online Study - 4주차. (0) | 2023.02.12 |
| [CloudNet@] Production Kubernetes Online Study - 3주차. (0) | 2023.02.05 |