
안녕하세요 늑대양입니다 :)
오늘부터 본격적으로 ML 학습을 진행합니다!! 🥸
[AI 데이터 사이언티스트 취업 완성 과정]의 44일차 일과를 정리하여 안내해드리도록 하겠습니다.

Day 44 시간표:
- 머신러닝 입문
- 머신러닝 입문 (실강)
Day 44 온라인 학습 범위:
- 14강
- 예상 학습 시간: 4:24:58
| 대주제(Part) | 중주제(Chapter) |
| Part.4 머신러닝 with Python | CH01_01. 머신러닝의 정의 |
| Part.4 머신러닝 with Python | CH01_02. Data Split |
| Part.4 머신러닝 with Python | CH01_03. training |
| Part.4 머신러닝 with Python | CH01_04. inference |
| Part.4 머신러닝 with Python | CH01_05. feature engineering |
| Part.4 머신러닝 with Python | CH01_06. loss function |
| Part.4 머신러닝 with Python | CH01_07. evaluation metric |
| Part.4 머신러닝 with Python | CH02_01. 머신러닝 프로젝트 수행방법 |
| Part.4 머신러닝 with Python | CH02_02. ML Framework Scikit-Learn |
| Part.4 머신러닝 with Python | CH03_01. 분류의 정의 |
| Part.4 머신러닝 with Python | CH03_02. Model1. Linear Classifier |
| Part.4 머신러닝 with Python | CH03_03. Model2. Logistic Regression |
| Part.4 머신러닝 with Python | CH03_04. Model3. Decision Tree |
| Part.4 머신러닝 with Python | CH03_05. Model4. Random Forest |
머신러닝 입문
Part.4 머신러닝 with python
Chapter.01 머신러닝 기초 개념
CH01_01. 머신러닝의 정의
머신러닝(Machine Learning, ML): 컴퓨터가 주어진 입력값(x)과 찾고자 하는 값(y) 사이의 관계를 모델링 하는 방법
Definition (from Wiki)
“A Computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.”

- 머신러닝이란, 경험 E를 통해서 주어진 T에 대해 P로 측정한 값이 향상되는 프로그램을 말합니다.
- 우리가 공부하는 것을 생각했을 때도 비슷합니다. 특정 과목 기말고사에서 주어진 족보를 풀어서 기말고사 점수가 향상되는 과정을 학습이라고 합니다. (human learning)
- 이 과정을 수학적으로는 주어진 입력(x)와 찾으려는 값(y) 사이의 관계 f를 찾는 문제로 정의합니다.
- 이 때, f는 function이며, 어떤 수식으로 표현되는 함수라기보다는 데이터와 데이터 사이의 관계라고 보는 것이 좋습니다.
Machine Learning Tasks (Taxanomy)

- Supervised Learning → 입력 데이터(x)와 그에 해당하는 정답(y)가 함께 삭습에 사용되는 방법론
- Classification - 주어진 데이터(x)를 몇 가지 종류(category, y)로 나누는 방법
- Regression - 주어진 데이터(x)와 관련이 있다고 생각하는 값(y) 사이의 관계를 찾는 방법
- Unsupervised Learning → 입력 데이터(x)만 학습에 사용되는 방법론 (y가 주어져 있지 않은 경우)
- Clustering - 주어진 데이터(x)를 몇 가지 그룹(subset of x)으로 나누는 방법
- Dimensionality Reduction - 주어진 데이터(x)의 중요한 정보들을 뽑아내는 방법
- Reinforcement Learning → 행동의 대상(agent)와 환경(environment) 사이의 interaction을 통해서 목표를 최대화(reward maximization)하는 학습 방법론
- Real-time decisions - 주어진 환경에 대해서 reaction을 하면서, 최적화가 필요한 방법론
- Game AI - AlphaGo(바둑), DeepBlue(체스), AlphaStar(Starcraft2), …
- ML workflow에서 이야기했던 것처럼 ML model은 어떤 데이터로 어떤 문제를 푸느냐에 따라 적절한 모델을 사용합니다.
- ML을 사용하는 문제 정의가 굉장히 중요합니다.
- 굳이 ML을 사용할 필요가 없는 경우에는 다른 방법론들로도 충분합니다. e.g. 통계 모델, EDA, A/B test, …
CH01_02. Data Split
data split: 학습에 사용할 데이터와 평가를 할 때, 사용할 데이터를 나누는 방법

- Data split은 train-test split을 이야기합니다. (train / test 데이터는 서로 겹치지 않는다)
- Training data는 학습에 사용하고 test data는 평가에 사용합니다.
- 직관적인 설명을 위해 예시를 하나 가정하겠습니다.
- 우리는 2022년 “머신러닝” 과목의 기말고사에서 100점을 맞고 싶습니다.
- 우리에겐 10년치 족보 문제와 답안이 함께 있습니다. (완벽한 답안이라고 가정합니다)
- 기말고사를 100점 맞기 위해서 어떻게 공부 방법을 설계하는 것이 좋을까요?
- 8년치를 열심히 공부하고(오답 정리), 2년치는 시험 직전 날에 풀어본다.
→ train - test split - 6년치를 열심히 공부하고(오답 정리), 그 때 마다 2년치를 풀어보고 점수를 체크한다. 그리고 시험 직전 날에 마지막 2년치를 풀어본다.
→ train - validation - test split
- 우리의 목표는 족보에 안나왔던 실제 기말고사를 100점 맞는 것이 목표입니다.
→ 안 풀어본 족보에 대한 예측(Prediction for UNSEEN data)
- 예측 성능을 올리는 것이 중요하다.
CH01_03. training
training: 머신러닝 모델이 데이터의 패턴을 파악하는 과정

- 어떤 모델을 사용하느냐에 따라서, 학습되는 정보가 다릅니다.
- 데이터를 보고 정해진 기준에 따라서 정보를 학습합니다.
- 학습된 정보를 기준으로 판단(=예측)을 합니다.
- 판단한 내용으로 성능을 평가합니다.
- 평가한 성능이 점차 향상되어야 합니다.

- 앞에서 보았던 그림을 예시로 들면, 빨간 선이 노란 선으로 바뀌어 가는 과정이라고 볼 수 있습니다.
- (조금 자세히) y = wx + b 라고 하면, w와 b가 직선을 결정합니다. (앞에서 이러한 변수들을 parameter라고 불렀습니다.)
- 주어진 데이터로부터 정보를 얻어서, 성능이 향상될 수 있는 방향으로 점차 정보(parameter)를 업데이트해 나가는 과정을 “학습(training)”이라고 합니다.
CH01_04. inference
Inference: 학습된 머신러닝 모델에 test data를 넣어서 결과를 내는 것

- 학습된 모델과 test data가 있어야 가능합니다.
- Inference에서는 학습이 일어나지 않습니다. (=오답 정리를 하지 않습니다)

- y = wx + b 라고 하면, w와 b가 직선을 결정합니다.
- w와 b는 이미 학습 과정에서 결정되었습니다.
- 정해진 모델에 “평가”만 이루어집니다.
- 이 때는 객관성을 유지하기 위해서 training data가 아닌 test data를 사용합니다.
- 우리의 학습 목표는 inference의 성능이 높아지길 기대하는 것입니다.
→ “Prediction for unseen data”
CH01_05. feature engineering

RECAP
- 데이터 마트까지 구성된 데이터를 input vector라고 부릅니다. (정형화 되어 있는 수치들)
- 이 input vector를 머신러닝 모델에 사용할 feature vector로 바꾸는 작업이 feature engineering입니다.
- feature vector란 input vector에서 머신러닝 모델이 보아야할 특징(feature)를 정의한 수치값들입니다.
- feature engineering에 따라 머신러닝 모델의 성능이 굉장히 크게 변할 수 있습니다.
- feature engineering을 할 때 체크해야 하는 사항들을 중점적으로 확인해야 합니다.
- feature vector가 표현되는 공간을 feature space라고 합니다.

- Feature engineering을 통해서, input data는 P(performance measure)를 높일 수 있는 좋은 수치정보로 변환이 됩니다.
- 이러한 수치정보(feature vector)를 만드는 방법은 feature extracion algorithm이라고 합니다.
- 대표적인 feature extraction algorithm에는 PCA(Principal Component Analysis), AutoEncoder등이 있습니다.
- 이미지, 텍스트 같은 특정 도메인에 있는 데이터는 해당 도메인의 특성에 맞게 feature extraction 방법들이 발전되어 왔습니다.
- 최근에는 Deep Learning을 사용하여 새롭게 feature를 생성하는 임베딩(Embedding) 방식을 사용합니다.
CH01_06. loss function
Loss function: 모델의 inference 결과(예측값)와 실제 값(y) 사이의 틀린 정도를 계산하는 함수

- ŷ(predicted value)와 $y$(target value) 사이의 차이를 계산해주는 함수.
- 덜 틀릴 수록(=차이가 적을 수록) 학습을 잘한 것입니다.
- 그럼 Loss function의 결과에 영향을 주는 변수는 무엇일까?
- → parameter! (weights)
- Loss function의 계산 결과가 가장 작아질 수 있는 parameter를 찾는 것이 학습의 목표가 됩니다.
Loss function optimization
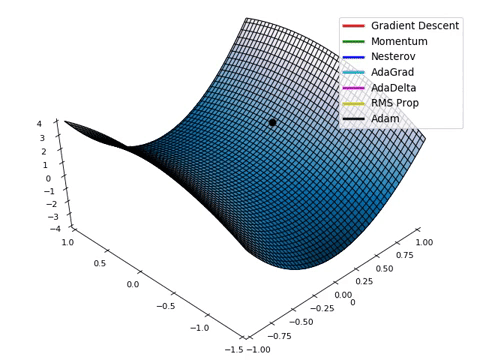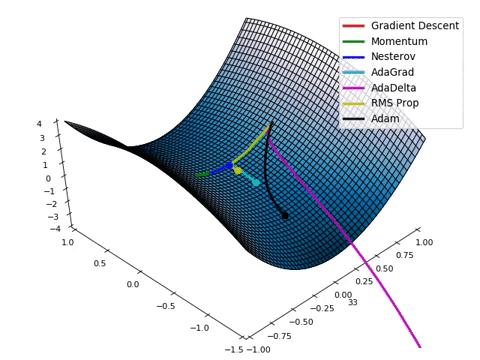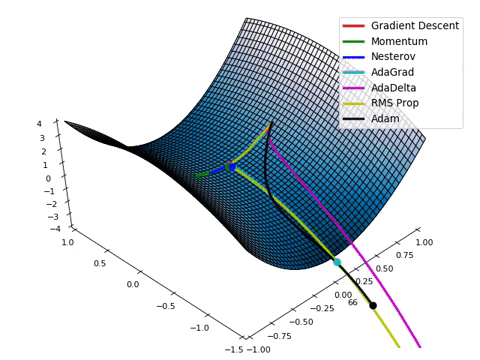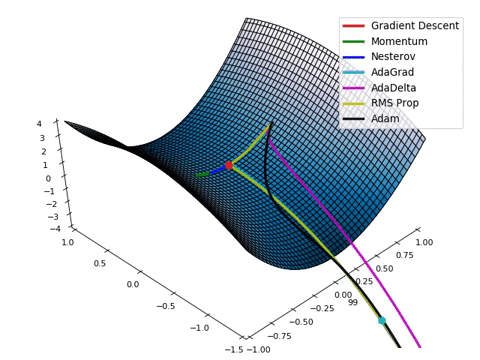
- Loss function이 최적의 값을 가질 수 있는 파라미터를 찾기 위해서는 파라미터를 적절하게 업데이트 해주어야 합니다.
- 성능이 향상되는 방향으로 파라미터를 업데이트 해주는 것이 중요합니다! (=loss가 줄어드는 방향)
- Loss space에서 최적의 파라미터 조합을 찾는 문제는 수학적으로 매우 어렵습니다. (고차원에서의 최적화 문제는 해답을 찾기가 어려움)
- 현실적으로 최적의 파라미터 조합을 찾을 수 있는 “Gradient Descent Algorithm” 이 제일 많이 사용됩니다.

- Gradient Descent algorithm은 산맥에서 임의의 포인트에 떨어졌을 때, 현재 서 있는 위치에서 가장 가파른 방향으로 한 발자국씩 내려가는 방법으로 최선을 다해 밑바닥으로 내려갈 수 있는 방법입니다.
- Practical하게 굉장히 좋은 파라미터 조합을 잘 찾아주며, 대부분의 머신러닝 모델에 적용되어 있는 최적화 방식입니다.
- Gradient Descent algorithm은 파라미터가 점차 loss function에서 최소값을 가질 수 있게 파라미터를 업데이트 해줍니다.
- 단, 무조건 global minimun(최소값)을 찾는 것은 아닙니다. local minimum(극소값)을 찾을 수도 있습니다.
(하지만, 극소값은 무조건 찾습니다)
CH01_07. evaluation metric
diffusion matrix

CH02_01. 머신러닝 프로젝트 수행방법
CH02_02. ML Framework Scikit-Learn
CH03_01. 분류의 정의
CH03_02. Model1. Linear Classifier
CH03_03. Model2. Logistic Regression
CH03_04. Model3. Decision Tree
CH03_05. Model4. Random Forest
머신러닝 입문
Machine Learning Workflow - 머신러닝을 이용한 프로젝트 수행방법 이해하기
목표: 머신러닝 워크플로우(머신러닝 문제를 푸는 것, 파이썬으로 해당 문제를 푸는 것)를 아는 것!
EDA 선에서 70% 정도 해결됨
머신러닝을 사용하는 두 가지 경우
- 데이터가 대용량 일 때 (10만 rows 이상, 엑셀로 보기 힘든 정도, 업계에서는 훨씬 더 큰 단위일 가능성 높음)
통계 분석이 어려워 지는 경우 - 약간의 유연함을 요구할 때 (통계 모델에 비해 유연할 때)
머신러닝을 이용한 문제해결은 예측을 하는 케이스가 많음
새로운 데이터가 기존 데이터의 패턴에 완전히 부합하지 않는 경우
데이터셋이 없으면 진행 자체가 불가능
Data-centric AI
데이터셋 대회 예제:
URL: https://dacon.io/competitions/official/235687/overview/description
시스템 품질 변화로 인한 사용자 불편 예지 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
개요:
- 문제정의의 중요성
- 데이터의 중요성 (납득 가능한 데이터)
- Competition으로 동기부여 가능
- 다른 사람들과 함께 진행하면서 얻을 수 있는 인사이트 공유
규칙:
- 평가 방식 (AUC 등)
- 평가 방식(결과 분석, 사용자 불만 접수 원인 분석 등등) > 분석 목표
머신러닝 문제 정의
- Classification
- Regression
- Clustering
- Ranking
- Generation
머신러닝의 정의
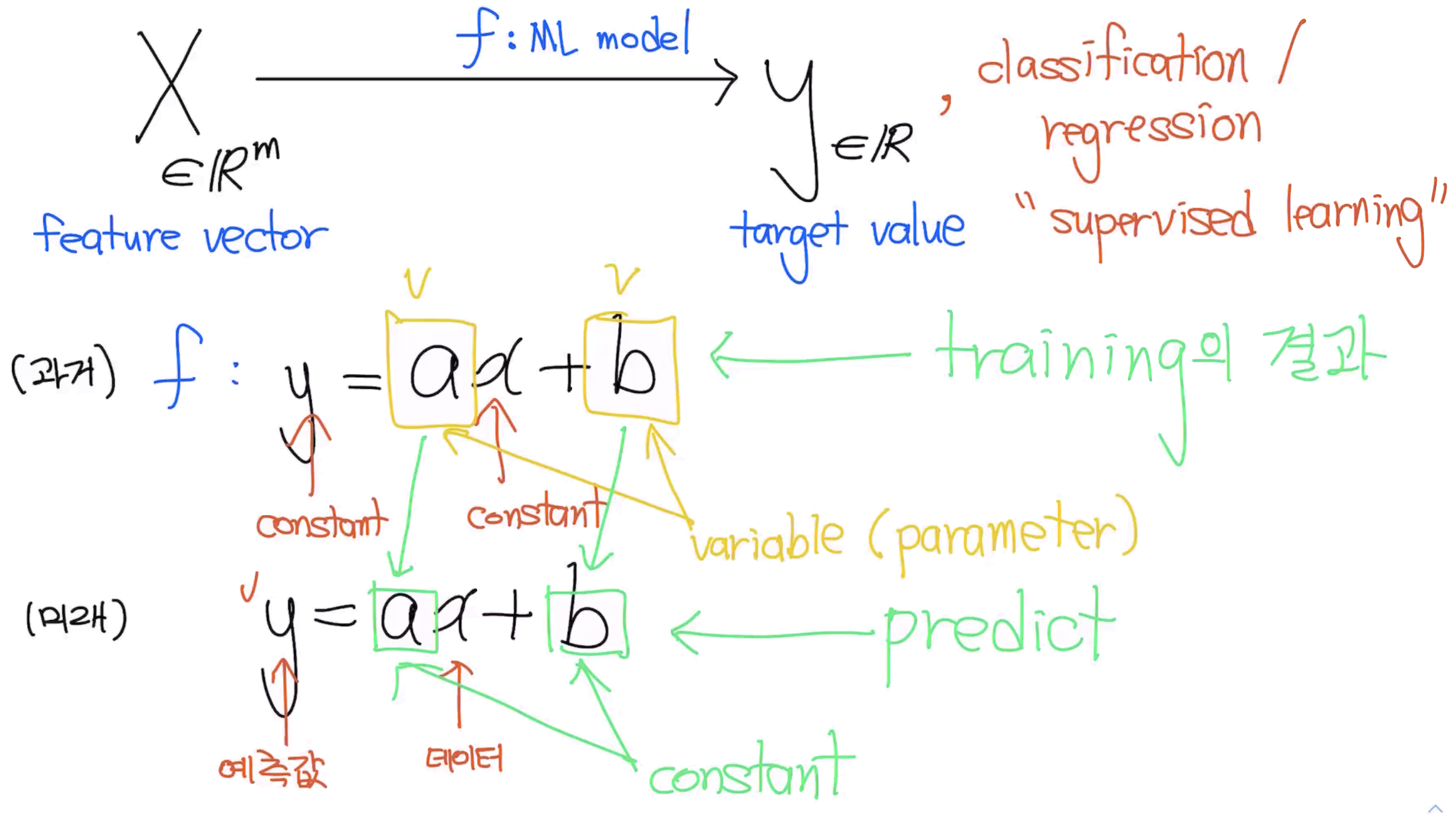
분류(Classification) - 컴퓨터가 데이터를 나누는 방법
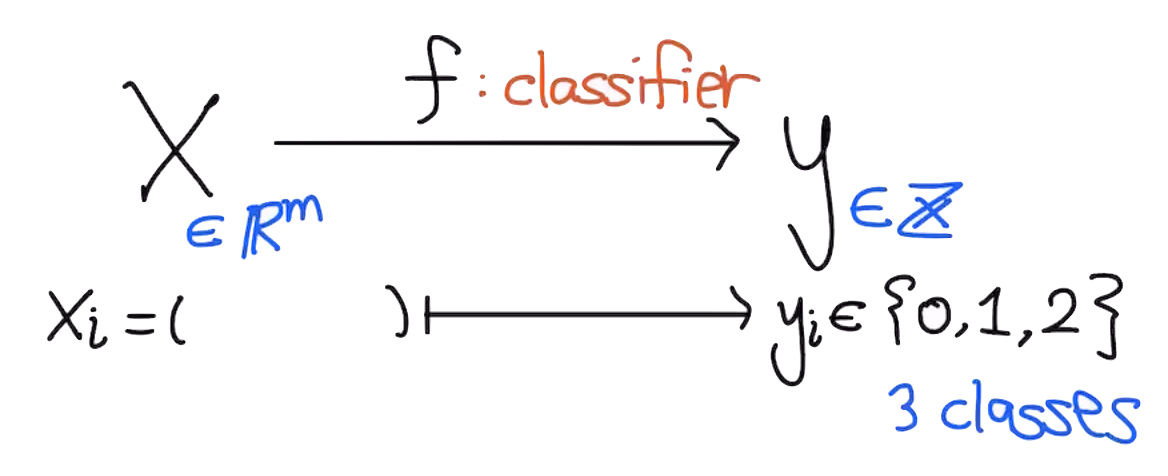
분류의 (비교적) 엄밀한 정의 (Formal Definition)
"Applications in which the training data comprises examples of the input vectors(X) along with their corresponding target vectors(y) are known as supervised learning problems. Cases in which the aim is to assign each input vector to one of a finite number of discrete categories, are called classification problems."
분류의 직관적인 의미
- 주어진 데이터(X)를 원하는 분류 기준(y)대로 나누는 방법
- 주어진 데이터(X)를 원하는 분류 기준(y = label)을 붙이는 방법
- 비슷한 특징을 가지는 데이터들을 같은 분류로 나누는 방법
e.g. 강아지 사진 1000장, 고양이 사진 1000장이 주어졌을 때(X), 강아지(=0)/고양이(=1)로(y) 나누는 작업
이미지 분류(Image Classification) - 이미지의 category를 결정하기

Linear Classifier - 가장 직관적이고 간단한 선형 분류 모델



긴 글 읽어주셔서 감사합니다 😍
'AI > [부트캠프] 데이터 사이언티스트 과정' 카테고리의 다른 글
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 46. (0) | 2022.10.28 |
|---|---|
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 45. (0) | 2022.10.27 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 43. (0) | 2022.10.25 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 42. (0) | 2022.10.24 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 41. (0) | 2022.10.21 |