
안녕하세요 늑대양입니다 :)
오늘은 [AI 데이터 사이언티스트 취업 완성 과정]의 9일차 일과를 정리하여 안내해드리도록 하겠습니다.

Day 9. 시간표:
- 선택 학습
- 랜덤 조별 회고
- 오프라인 강의: [웹크롤링 기본 (파이썬 라이브러리)]
선택 학습:
선택 학습 시간을 활용하여, 한 주간 학습한 부분을 복습하고 익숙해지는 시간을 가졌습니다!
Day.10 선택 학습 시간에는 numpy, pandas, seaborn에 대해 학습할 예정입니다.
랜덤 조별 회고:
일주일 동안 학습한 내용을 바탕으로 회고를 진행하였습니다.
조는 랜덤으로 구성되었으며, 게더타운 스터디룸에서 아래의 네 가지 주제로 회고를 하였습니다.
- 간단한 자기소개
- [프로그래밍 기초 : Python] 강의에서 배운 점, 어려운 점
- 어려움을 극복한(또는 극복할)방법
- 수업 진행하면서 힘든 점, 건의사항

조원과 회고를 진행하며, '무엇을 배웠는지', '어떤 부분에서 어려운지', 어떻게 극복하였는지' 등을 편안하게 공유할 수 있어 좋은 시간이었습니다.
Day 9. 프로그래밍 기초 : Python
5. I/O 실습:
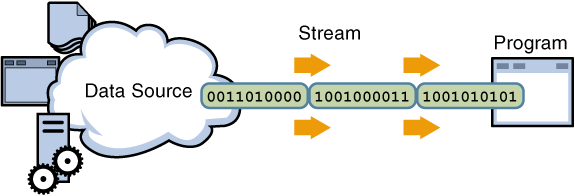
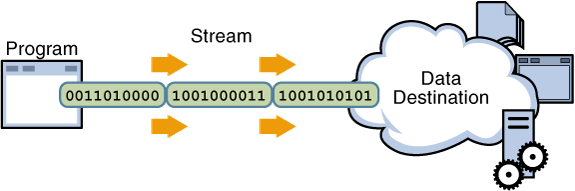
1. STDIN / STDOUT
프로그램은 켜지면 메인 메모리에 올라감 > CPU 처리 > 다시 메인 메모리 > 실행
데이터는 스토리지에 저장 > 사용할 때 꺼냄
# print 함수 응용
# 1. formatting
name = '홍길동'
bod = '220901'
pn = '311111'
print(f"{name}님의 주민등록번호는 {bod}-{pn}입니다.")
>홍길동님의 주민등록번호는 220901-311111입니다.
# 2. 출력 양식의 마지막을 지정하는 방법
print(f"{name}님의 주민등록번호는 {bod}-{pn}입니다.", end=";")
print("a")
>홍길동님의 주민등록번호는 220901-311111입니다.;a
# list comprehension 예제
# 위의 코드는 아래와 같다. 위의 코드가 훨씬 간단한 것을 확인할 수 있다. 익숙해져서 list comprehension을 사용하도록 하자.
# L = []
# for i in range(1, 5):
# L.append(i+2)
# L
L = [i+2 for i in range(1, 5)]
print(L)
print('-' * 10)
L2 = [x.lower() for x in ["Hello", "Kim", "PyTHON", "Wednesday"]]
print(L2)
print('-' * 10)
L3 = []
for i in ["Hello", "Kim", "PyTHON", "Wednesday"]:
L3.append(i.lower())
print(L3)
>[3, 4, 5, 6]
----------
['hello', 'kim', 'python', 'wednesday']
----------
['hello', 'kim', 'python', 'wednesday']
List comprehension은 자주 사용하니 익숙해지도록하자!!
2. File I/O:

- file I/O란 프로그램에서 파일을 저장하고 불러오는 모든 것들을 의미합니다
- file에는 txt, png, json, xlsx 등 여러가지 종류가 있습니다
- 파일의 경로는 크게 절대경로와 상대경로로 구분됩니다
- 절대경로: / 를 기준으로 현재 파일의 위치 경로
- 상대경로: 코드(프로그램)가 실행되고 있는 위치를 기준으로 한 파일의 경로
- 그 중에서 가장 간단하게 사용할 수 있는 데이터는 txt 파일입니다
파일을 불러올 때, 생기는 분노 포인트🔥:
1. 경로를 인식하지 못하는 경우:
- 경로에 영어가 아닌 다른 글자(주로 한글)이 있는 경우에 인식하지 못하는 케이스가 있음
- 경로가 진짜로 틀린경우
e.g. '/' '\' (보통은 오타)
2. 파일 내부의 데이터가 한글 텍스트인 경우:
- 기본적으로 텍스트를 'utf-8'이라는 방식으로 인코딩함
- 윈도우 + 한글: cp949
# 원론적으론 open 하고 cloase 해줘야하지만 with open을 통해 열 경우, 휘리릭 열 수 있다
# f.read()를 통해 data 폴더안에 있는 test.txt를 read mode로 열어봅니다.
# read - r, (over)write - r, append - a
with open('test.txt', 'r') as f: # 이걸 통채로 외워도 좋다!, f 자리에는 다른 것이와도 가능!
print(f.read()) # f.read(): 갖고 있는 파일의 모든 문자를 하나의 string으로 읽어옴
>아
휴
아이구
아이쿠
아이고
어
나
우리
저희
따라
의해
을
를
에
의
가
으로
로
에게
뿐이다
의거하여
근거하여
입각하여
기준으로
예하면
예를 들면
예를 들자면
with open('test.txt', 'r') as f: # encoding 관련 에러가 발생할 경우 encoding='utf-8' 부분을 추가해주자!
# print(f.read()) # f.read(): 갖고 있는 파일의 모든 문자를 하나의 string으로 읽어옴
s = f.read()
s
>'아\n휴\n아이구\n아이쿠\n아이고\n어\n나\n우리\n저희\n따라\n의해\n을\n를\n에\n의\n가\n으로\n로\n에게\n뿐이다\n의거하여\n근거하여\n입각하여\n기준으로\n예하면\n예를 들면\n예를 들자면'
# f.readline()를 통해 data 폴더안에 있는 test.txt를 read mode로 열어봅니다.
with open('test.txt', 'r') as f:
s = f.readline() # readline() 정의: \n 까지 읽어오기 (첫 번째 줄을 읽어옴)
s
>'아\n'
# f.readlines()를 통해 data 폴더안에 있는 test.txt를 read mode로 열어봅니다.
with open('test.txt', 'r') as f:
s = f.readlines() # 한줄 한줄 원소로해서 가져오는 readlines()
s
>['아\n',
'휴\n',
'아이구\n',
'아이쿠\n',
'아이고\n',
'어\n',
'나\n',
'우리\n',
'저희\n',
'따라\n',
'의해\n',
'을\n',
'를\n',
'에\n',
'의\n',
'가\n',
'으로\n',
'로\n',
'에게\n',
'뿐이다\n',
'의거하여\n',
'근거하여\n',
'입각하여\n',
'기준으로\n',
'예하면\n',
'예를 들면\n',
'예를 들자면']
# for문을 통해 data 폴더안에 있는 test.txt를 read mode로 열어서 출력해봅니다.
with open('test.txt', 'r') as f:
for line in f:
print(line)
>아
휴
아이구
아이쿠
아이고
어
나
우리
저희
따라
의해
을
를
에
의
가
으로
로
에게
뿐이다
의거하여
근거하여
입각하여
기준으로
예하면
예를 들면
예를 들자면
# for문을 통해 data 폴더안에 있는 test.txt를 read mode로 열어서 출력해봅니다.
L = []
with open('test.txt', 'r') as f:
for line in f:
L.append(line)
L
>['아\n',
'휴\n',
'아이구\n',
'아이쿠\n',
'아이고\n',
'어\n',
'나\n',
'우리\n',
'저희\n',
'따라\n',
'의해\n',
'을\n',
'를\n',
'에\n',
'의\n',
'가\n',
'으로\n',
'로\n',
'에게\n',
'뿐이다\n',
'의거하여\n',
'근거하여\n',
'입각하여\n',
'기준으로\n',
'예하면\n',
'예를 들면\n',
'예를 들자면']
# list comprehension 활용
with open('test.txt', 'r') as f:
L = [line for line in f]
L
>['아\n',
'휴\n',
'아이구\n',
'아이쿠\n',
'아이고\n',
'어\n',
'나\n',
'우리\n',
'저희\n',
'따라\n',
'의해\n',
'을\n',
'를\n',
'에\n',
'의\n',
'가\n',
'으로\n',
'로\n',
'에게\n',
'뿐이다\n',
'의거하여\n',
'근거하여\n',
'입각하여\n',
'기준으로\n',
'예하면\n',
'예를 들면\n',
'예를 들자면']
# List comprehension 활용 예제 - 2
with open('test.txt', 'r') as f:
L = [line.strip() for line in f]
L
>['아',
'휴',
'아이구',
'아이쿠',
'아이고',
'어',
'나',
'우리',
'저희',
'따라',
'의해',
'을',
'를',
'에',
'의',
'가',
'으로',
'로',
'에게',
'뿐이다',
'의거하여',
'근거하여',
'입각하여',
'기준으로',
'예하면',
'예를 들면',
'예를 들자면']
# File I/O & list comprehension 예제!
output = []
# test.txt를 read mode로 열고 할 일이 끝나면 자동으로 닫는다.
with open('test.txt', 'r') as f:
data = [line.strip() for line in f]
# print(data)
# 두글자 이상인 텍스트만 output list에 저장한다.
output = [line for line in data if len(line) >= 2]
# for word in data:
# word = word.strip()
# if len(word) >= 1:
# output.append(word)
# print(output)
# result.txt로 output list에 있는 내용을 저장하기 위해 write mode로 열었다.
with open('result.txt', 'w') as f:
for line in output:
f.write(line + '\n') # 괄호 안에 들어가는 것을 result.txt 파일로 저장!
# print() 함수의 세번째 기능인 file output!
with open('result.txt', 'w') as f:
for line in output:
print(line) # standard output
print(line, file=f) # file output!!!

pickle 라이브러리를 통해서 파이썬 object 자체를 저장하기:
# 일반적인 파일 저장하기
with open('test.txt', 'r') as f:
output = [line for line in f]
output
# pickle 라이브러리를 활용한 object 자체 저장!
# 대용량 데이터에 대해서는 사용하지 않는 것을 추천
# 대용량 데이터에 대해서는 불필요하게 용량이 늘어남
import pickle # 피클이 없으면 pk 파일을 읽을 수 없음, 0과 1로 이루어진 신기한 것으로 파이썬 변수 저장 > 직렬화(serialization)
# pickle 라이브러리를 이용한 저장!
# 모델을 그대로 저장하고 싶을 때, 피클을 사용!
# 100% 똑같은 파일을 저장하는 방법!
with open("result.pk", 'wb') as f: # b 는 피클에서만 사용하는 특수한 모드, binary
pickle.dump(output, f) # 덤프를 써서 output을 f에 저장!
>(result.pk 파일 저장)
# pickle 라이브러리를 이용한 로드!
with open("result.pk", 'rb') as f: # rb: read as binary
output2 = pickle.load(f) # f를 로드하자!
output2 # 리스트가 똑같이 출력!!, 변수를 그대로 저장! > 그대로 출력!, 파이썬에서 만드는 모든 변수가 전부 다 가능!!
>['아\n',
'휴\n',
'아이구\n',
'아이쿠\n',
'아이고\n',
'어\n',
'나\n',
'우리\n',
'저희\n',
'따라\n',
'의해\n',
'을\n',
'를\n',
'에\n',
'의\n',
'가\n',
'으로\n',
'로\n',
'에게\n',
'뿐이다\n',
'의거하여\n',
'근거하여\n',
'입각하여\n',
'기준으로\n',
'예하면\n',
'예를 들면\n',
'예를 들자면']

긴 글 읽어주셔서 감사합니다 :)
'AI > [부트캠프] 데이터 사이언티스트 과정' 카테고리의 다른 글
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 11. (0) | 2022.09.05 |
|---|---|
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 10. (0) | 2022.09.02 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 8. (0) | 2022.08.31 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 7. (0) | 2022.08.30 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 6. (0) | 2022.08.29 |