
728x90
반응형
안녕하세요 늑대양입니다.
드디어 본격적으로 딥러닝 학습을 시작합니다!! 🥳
오늘은 [AI 데이터 사이언티스트 취업 완성 과정]의 68일차 일과를 정리하여 안내해드리도록 하겠습니다.

Day 68 시간표:
- 딥러닝 입문
- 딥러닝 입문 - 오프라인 강의
Day 68 온라인 학습 범위:
- 12강
- 예상 학습 시간: 3:22:37
| 중주제(Chapter) | 소주제(Clip) |
| Part 8. 딥러닝 에센스 | CH02_10. 딥러닝 핵심 1 _ 뉴럴 네트워크 - Pytorch 실습 _ MLP 응용 |
| Part 8. 딥러닝 에센스 | CH02_11. 딥러닝 핵심 1 _ 뉴럴 네트워크 - Tensorflow 기본 |
| Part 8. 딥러닝 에센스 | CH02_12. 딥러닝 핵심 1 _ 뉴럴 네트워크 - Tensorflow 실습 _ MLP 기본 |
| Part 8. 딥러닝 에센스 | CH02_13. 딥러닝 핵심 1 _ 뉴럴 네트워크 - Tensorflow 실습 _ MLP 응용 |
| Part 8. 딥러닝 에센스 | CH02_14. 딥러닝 핵심 1 _ 뉴럴 네트워크 - Pytorch 실습_ wandb를 활용한 시각화 |
| Part 8. 딥러닝 에센스 | CH02_15. 딥러닝 핵심 1 _ 뉴럴 네트워크 - Tensorflow 실습_ wandb를 활용한 시각화 |
| Part 8. 딥러닝 에센스 | CH03_01. 이미지분류 |
| Part 8. 딥러닝 에센스 | CH03_02. 데이터증강기법 |
| Part 8. 딥러닝 에센스 | CH03_03. CNN기본개념1 |
| Part 8. 딥러닝 에센스 | CH03_04. CNN기본개념2 |
| Part 8. 딥러닝 에센스 | CH03_05. MLP와 CNN비교 |
| Part 8. 딥러닝 에센스 | CH03_06. Hyperparameter |
딥러닝 입문
Perceptron
최초로 제안된 Neural Model

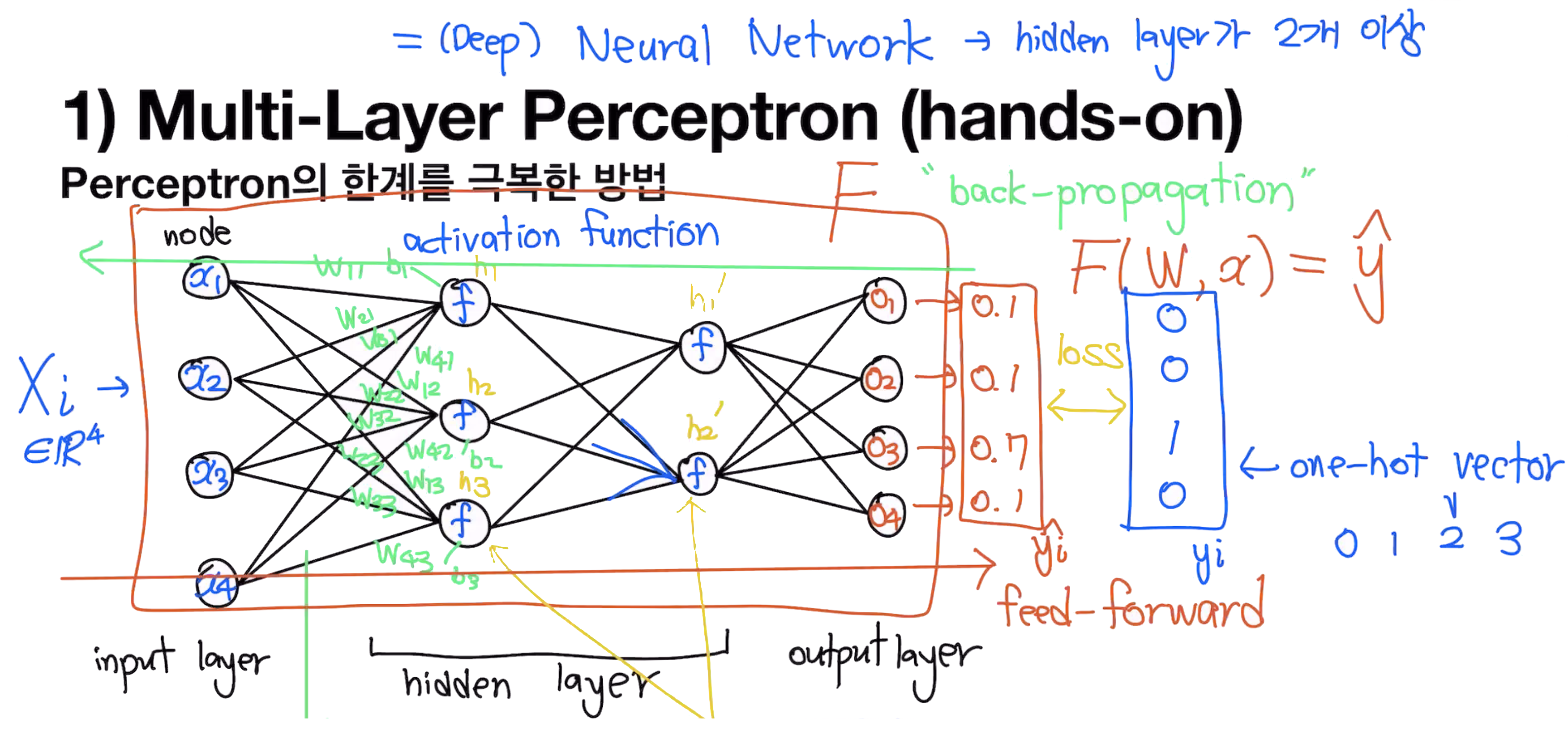
Multi-Layer Perceptron
Perceptron의 한계를 극복한 방법

c.f) cs231n, Deep Learning for Computer Vision - Lecture 4 - Back propagation
- chain rule(합성함수의 미분)
- partial derivatives(편미분)
- jacobian matrix(자코비안 행렬)
- http://cs231n.stanford.edu/index.html
Stanford University CS231n: Deep Learning for Computer Vision
Course Description Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving cars. Core to many of these applications are visual recognition tasks such as image
cs231n.stanford.edu
Active Function
계산된 정보를 활성화하는 기준
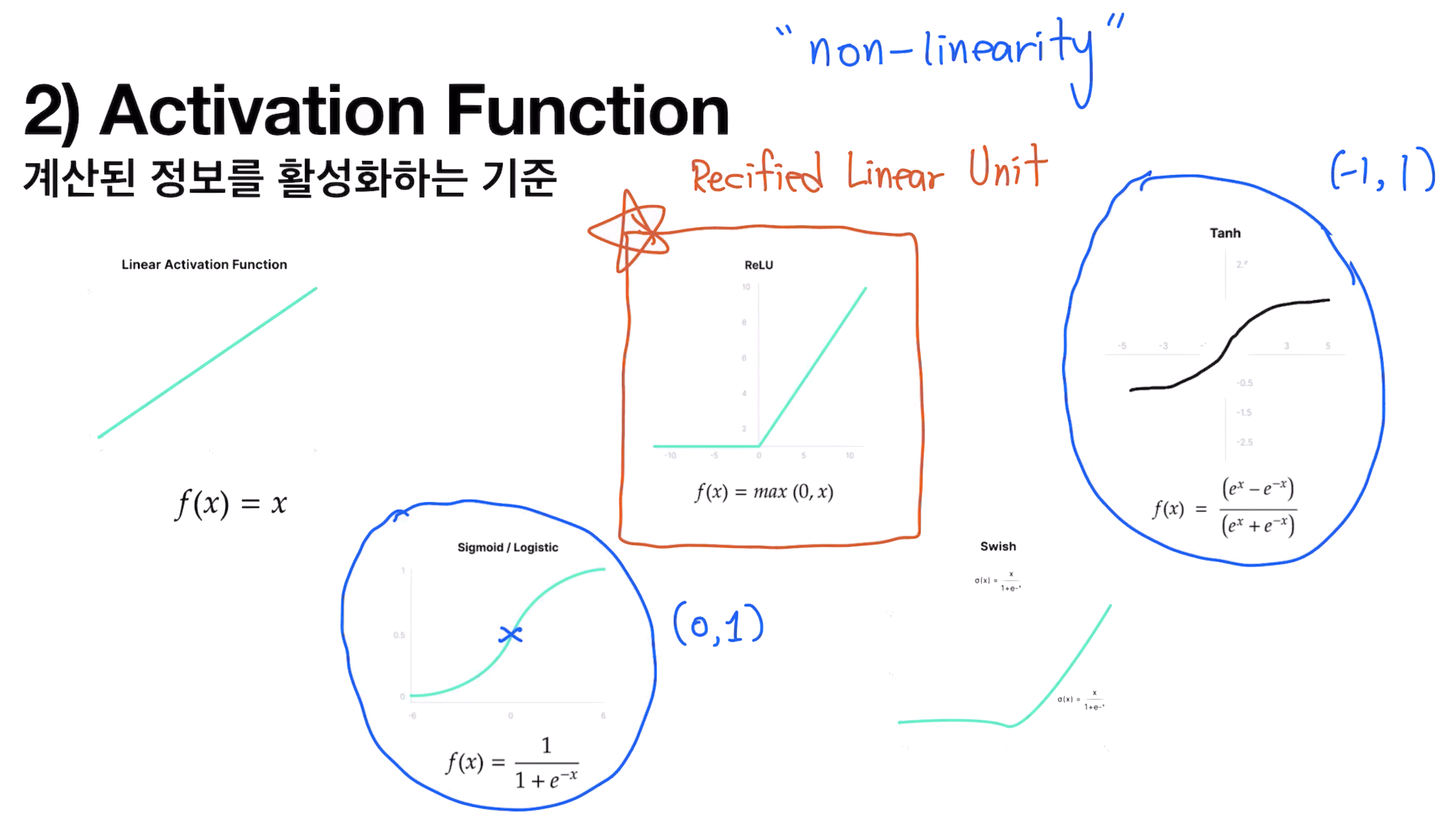
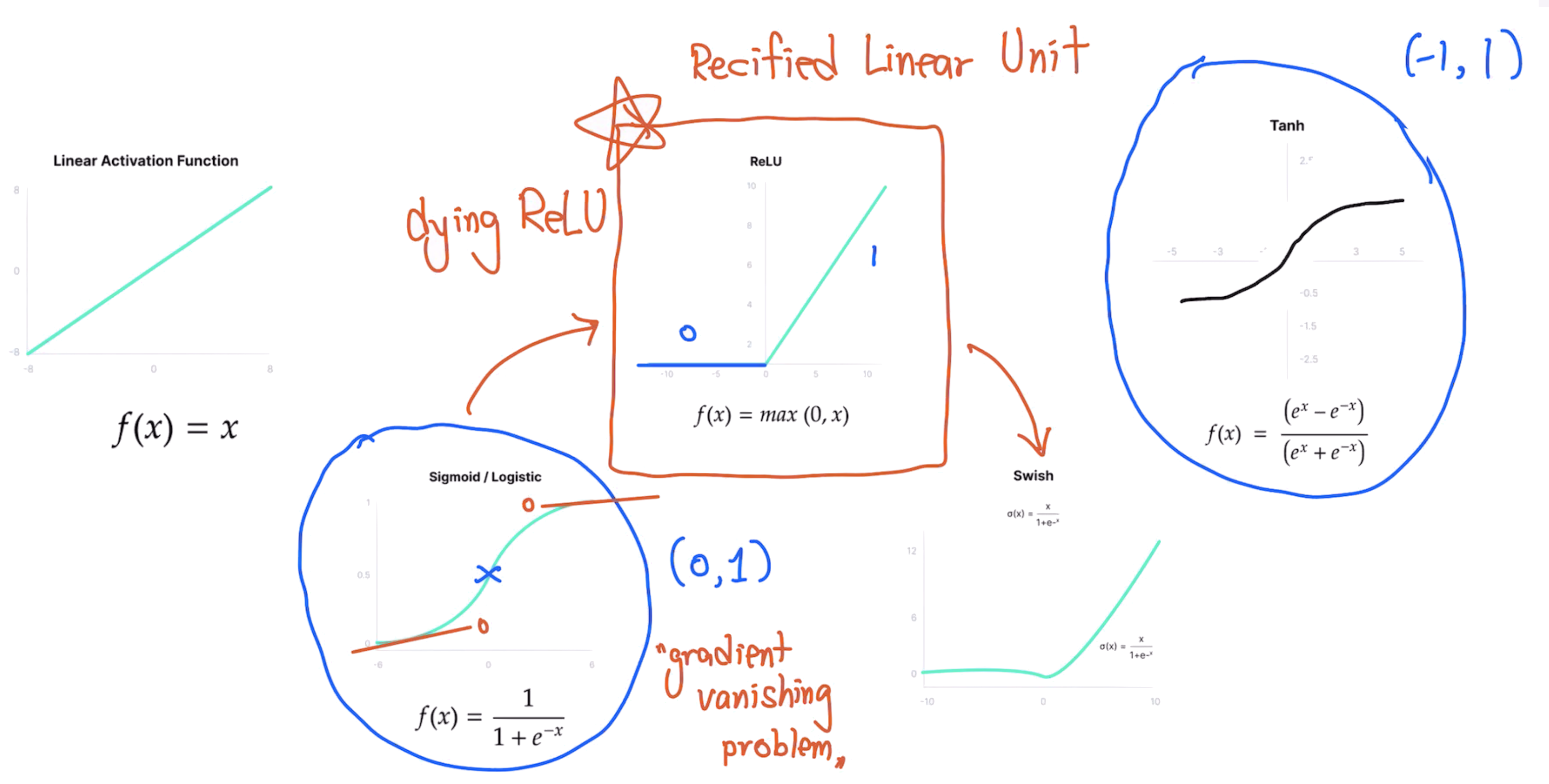
Output & Loss function
예측값을 계산하는 함수, Softmax
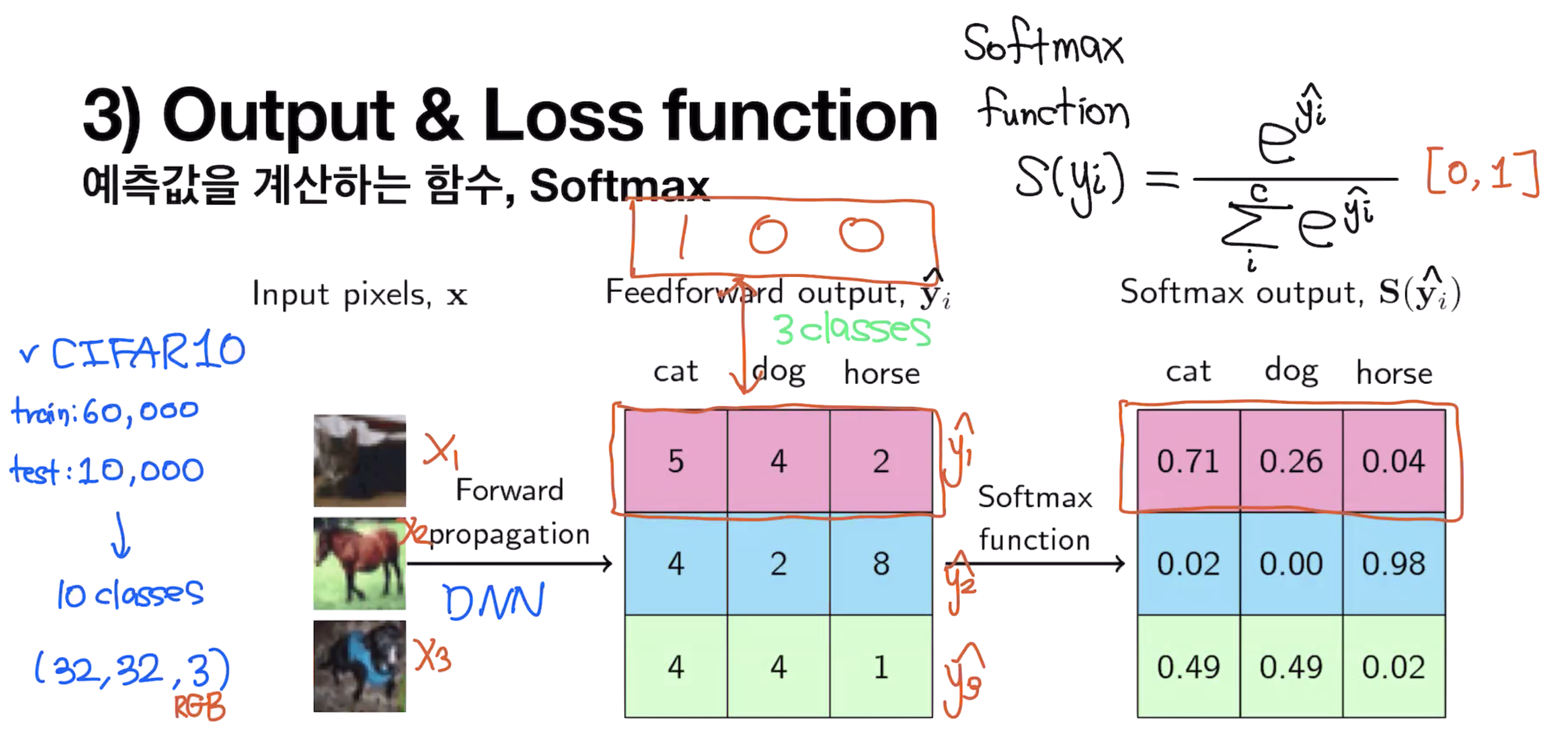
Cross-entropy
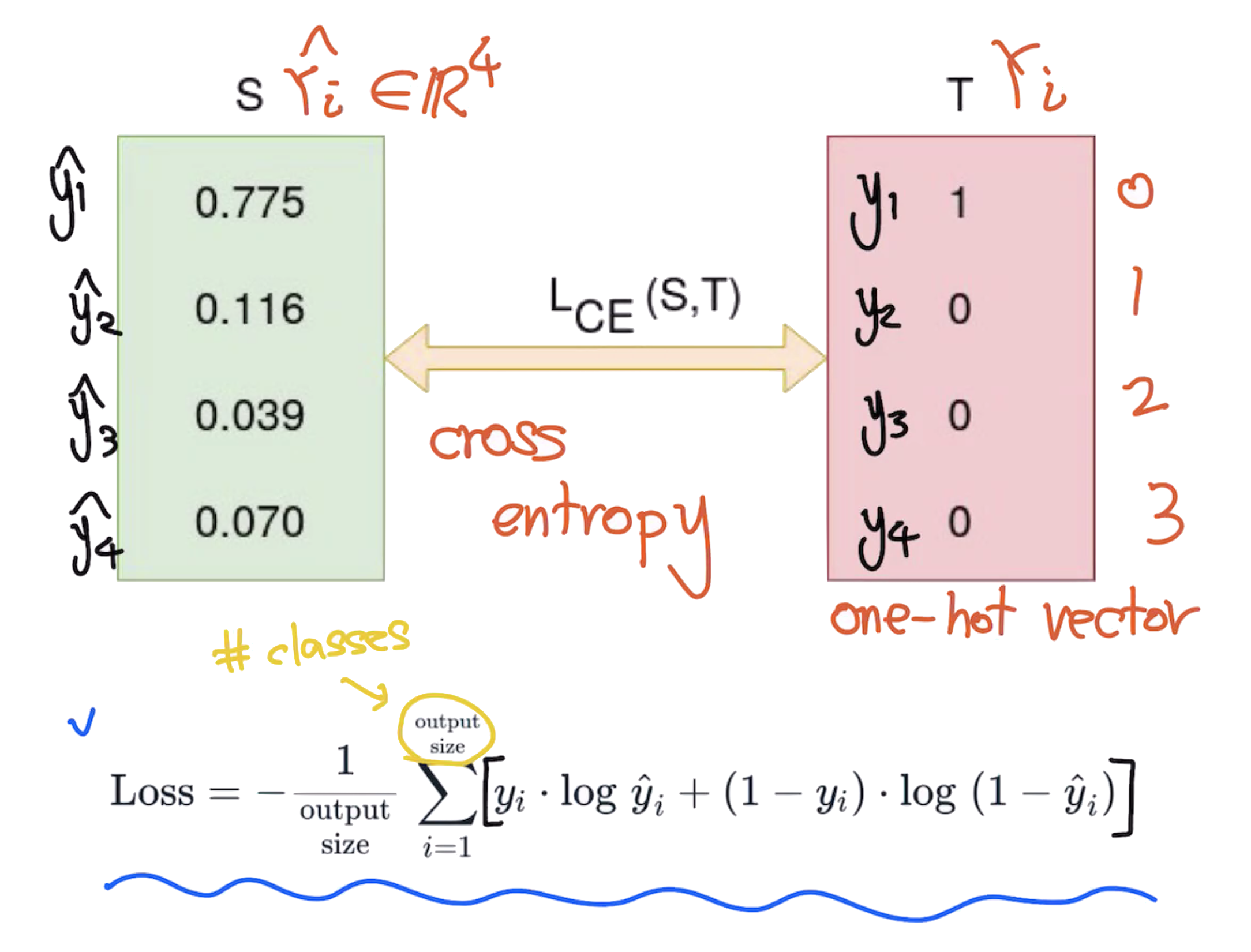
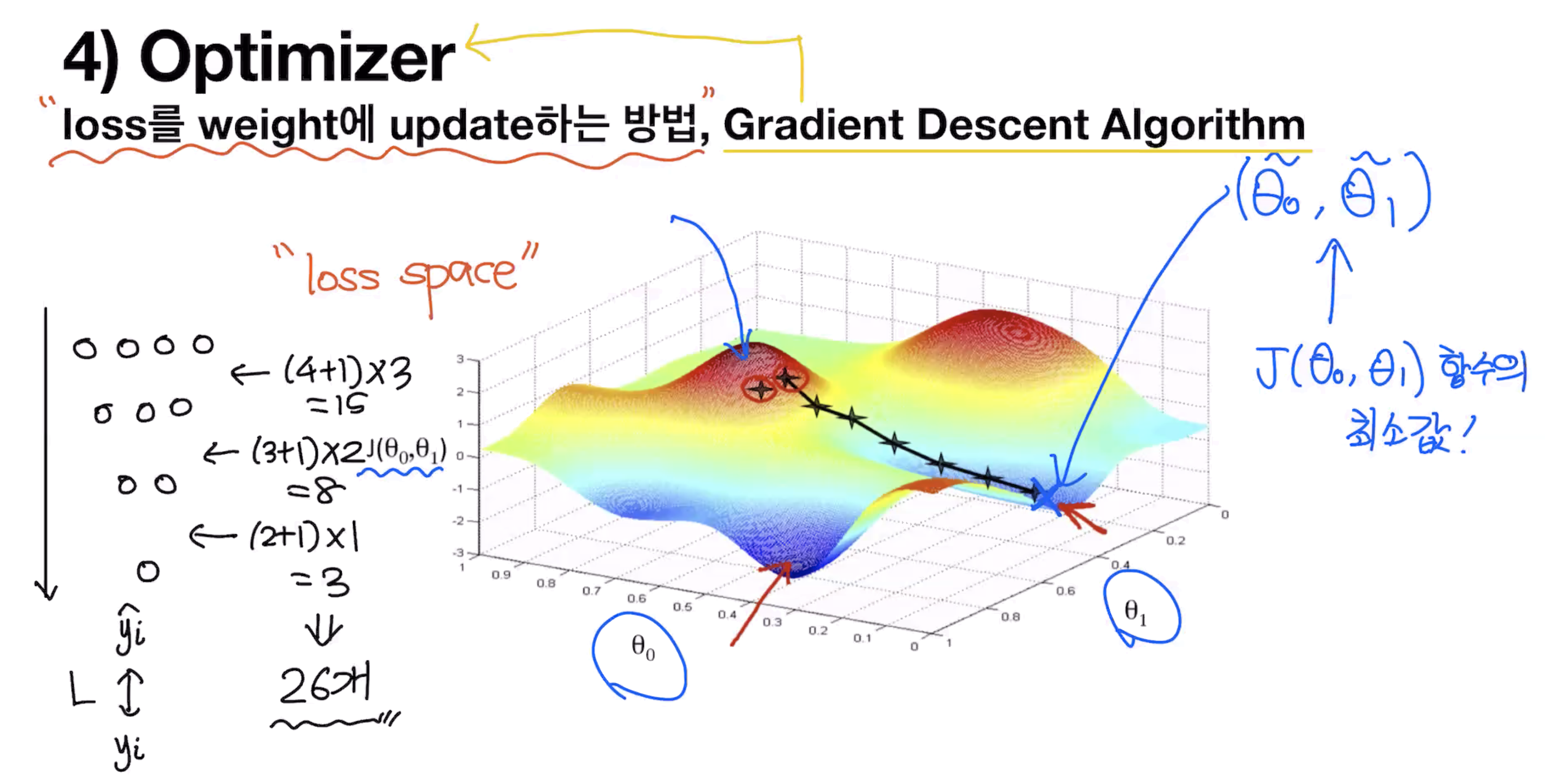
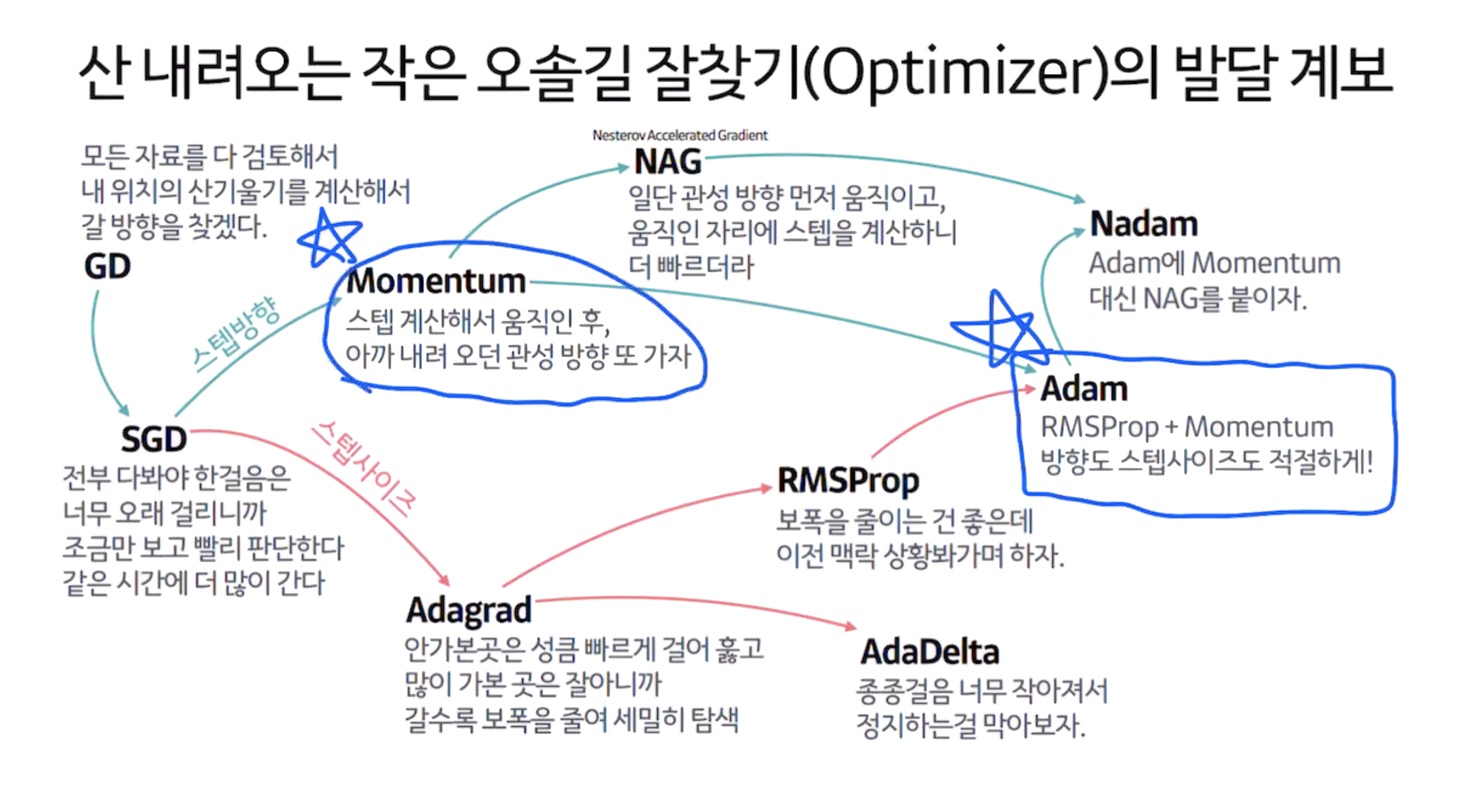
Optimizer
"Loss를 weight에 update하는 방법", Gradient Descent Algorithm
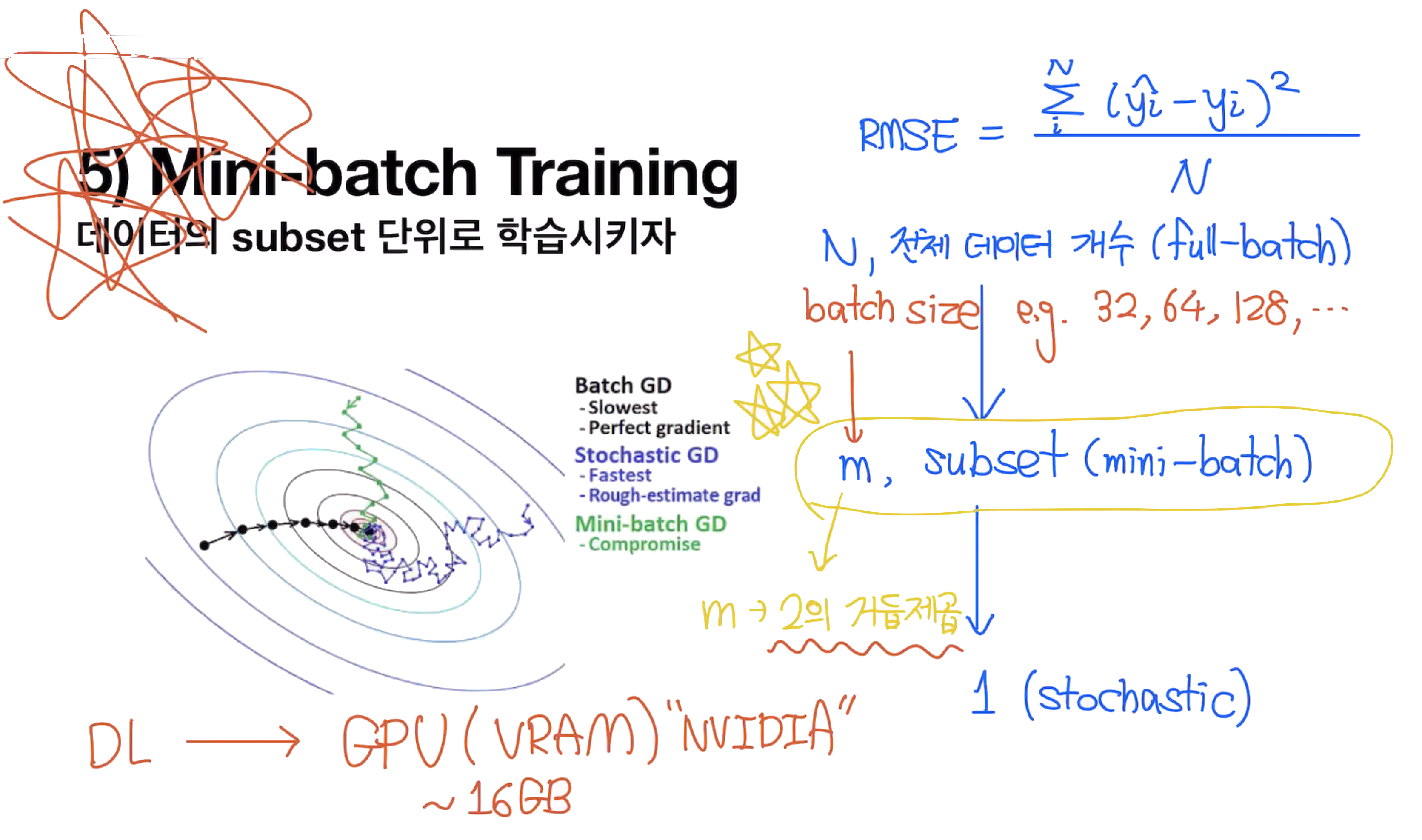
Mini-batch Training
데이터의 subset 단위로 학습시키자

긴 글 읽어주셔서 감사합니다 🫠
728x90
반응형
'AI > [부트캠프] 데이터 사이언티스트 과정' 카테고리의 다른 글
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 70. (0) | 2022.12.01 |
|---|---|
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 69. (0) | 2022.11.30 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 67. (0) | 2022.11.28 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 66. (0) | 2022.11.25 |
| [Megabyte School : AI 데이터 사이언티스트 취업 완성 과정] Day 65. (0) | 2022.11.24 |